
 Roeland Hofkens, Chief Product & Technology Officer, LanguageWire
Roeland Hofkens, Chief Product & Technology Officer, LanguageWire
Grote taalmodellen (LLM's, Large Language Models) hebben niet meteen de beste naam wat betreft de beveiliging en privacy van gegevens. Je hebt misschien wel gehoord dat er uit ChatGPT persoonlijke gegevens gelekt zijn. Gegevens van klant A kwamen namelijk terecht in chatantwoorden voor klant B, en dat maakt heel wat zakelijke gebruikers terecht ongerust. Hoe kunnen wij er dan voor zorgen dat we LLM-technologie veilig gebruiken, in overeenstemming met het Europese recht?
Het goede nieuws is dat LLM's niet inherent onveilig zijn. Een groot model zal niet automatisch en per definitie privégegevens gaan lekken. Dergelijke risico's zijn allemaal te wijten aan de manier waarop een dienstenleverancier met het model omgaat en het beheert. De twee belangrijkste risico's voor gegevensbeveiliging en -privacy in een LLM-context zijn:
Het model 'lekt' persoonlijke of vertrouwelijke gegevens van de ene klantcontext naar de andere. Dit gebeurt bijvoorbeeld wanneer het gemeenschappelijke basismodel of het op instructies gebaseerde model automatisch wordt getraind met invoergegevens die afkomstig zijn van klanten. In dit geval kan een vraag van klant B ertoe leiden dat een model letterlijk antwoordt met gegevens van klant A. Lekken kunnen ook te wijten zijn aan een slechte technische architectuur, zoals het gebruik van een generische cache die de context van de klant niet respecteert.
Deze risico's hebben meestal te maken met de manier waarop de aanbieder van een model de infrastructuur beheert en hoe hij de gegevens opslaat die klanten het model toesturen. Als de provider de invoer van de klant zonder meer overneemt en voor onbepaalde tijd opslaat (bv. voor het trainen van het model), bestaat er een aanzienlijk risico dat hij persoonsgegevens voor een lange periode opslaat. Dit kan leiden tot problemen met de AVG als we persoonsgegevens uit al onze eigen systemen en uit die van subcontractanten moeten verwijderen.
In deze blog kijken we echter alleen naar de risico's met betrekking tot gegevens en privacy. Deze post laat andere risico's, zoals hallucinaties, schadelijke inhoud, toxiciteit enz. omtrent de 'drie H's' (handig, ongevaarlijk, eerlijk (in het Engels: helpful, harmless, honest)), buiten beschouwing.
Laten we beginnen met het risico op gegevenslekken. Zoals we al uit de doeken hebben gedaan in onze vorige blogpost, Grote taalmodellen en machinevertaling: het tijdperk van hyperpersonalisatie, het finetunen van het LLM met je eigen gegevens is een goed idee. Dit zal de kwaliteit van de LLM-output immers aanzienlijk verbeteren. Je hoeft alleen maar zeker te zijn dat jij de enige bent die deze aanpassingen kan gebruiken. Dit wil zeggen dat wij geen gedeelde databases of getrainde modellen mogen verrijken met vertrouwelijke of particuliere klantgegevens!
Zoals de naam al aangeeft, zijn Grote taalmodellen erg groot. Het zou dus werkelijk onbetaalbaar zijn om voor al onze klanten een volledig gepersonaliseerd LLM uit te bouwen. Gelukkig bestaan er nog andere, efficiëntere technieken.
Bij LanguageWire werken we met PEFT met LoRA en in-context learning. Deze technieken stellen ons in staat om een klantneutraal basismodel te handhaven en de aanpassingen tijdens de looptijd of in de prompt in te laden. Op die manier houden we klantgegevens op het fysieke en het logisch niveau van elkaar gescheiden. Het is simpelweg onmogelijk dat gegevens van klant A worden gelekt naar klant B: afhankelijk van wie de aanvraag doet, heeft het model enkel toegang tot de gegevens die relevant zijn voor die klant.
Dit zie je terug in afbeelding 1.
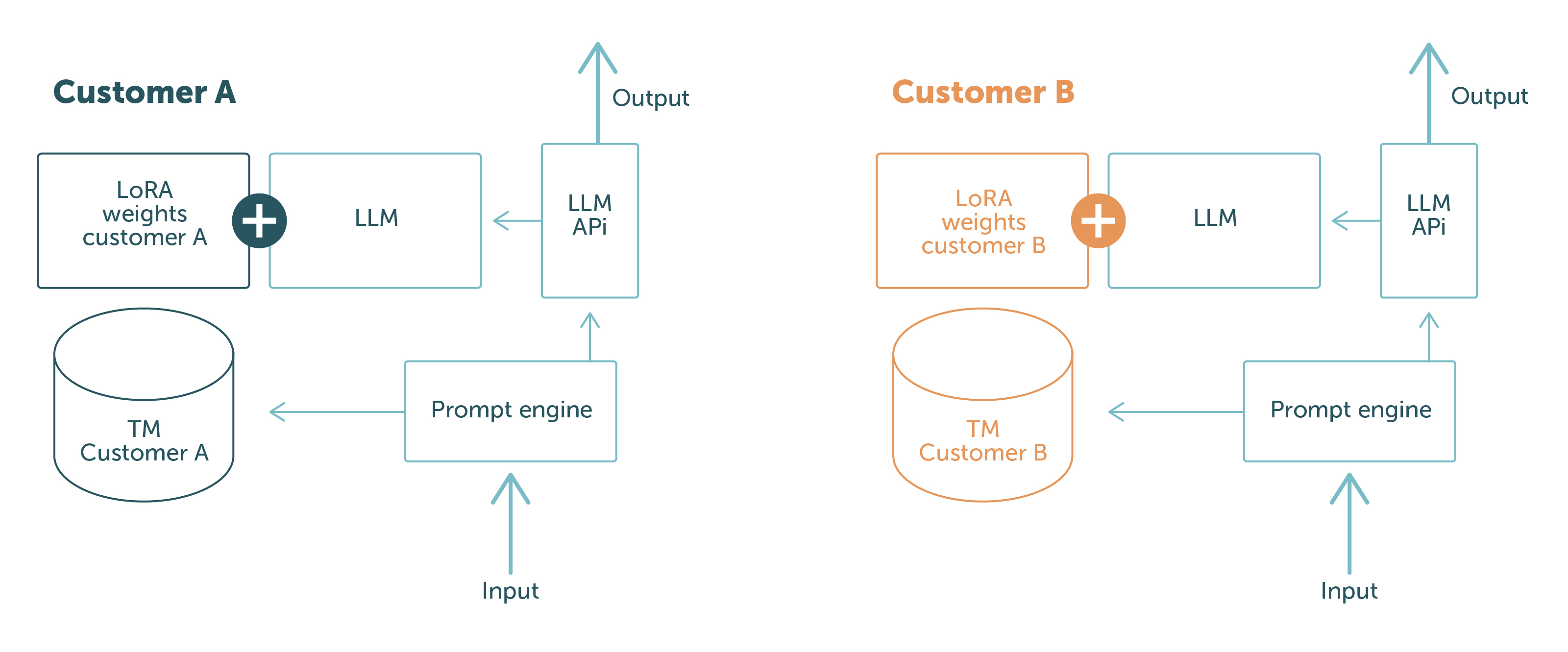
De delen in het blauw zijn de softwareonderdelen en -gegevens die tussen verschillende klantaanvragen worden uitgewisseld. De delen met een andere kleur zijn klantspecifiek. Hieruit blijkt duidelijk dat de klantgegevens strikt gescheiden zijn:
Dankzij deze opbouw kunnen we onze klanten garanderen dat hun gegevens nooit bij een andere klant terecht zullen komen. Probleem opgelost!
Om ervoor te zorgen dat we geen nalevingsrisico's lopen, werkt het technische team van LanguageWire volgens een duidelijke reeks richtlijnen wat betreft LLM's en andere AI-modellen:
Wij handhaven deze richtlijnen door zeer zorgvuldig om te gaan met onze activiteiten en infrastructuur. LanguageWire gebruikt twee benaderingen bij het uitbaten van LLM's.
De eerste is om het LLM volledig te laten uitbaten door systeembetrouwbaarheidstechnici en producttechnici van LW. Dit betekent dat we alles wat de infrastructuur betreft, zoals GPU's, networking, modelopslag, containers, enz., zelf voorzien en inrichten. Er zijn geen derde partijen bij betrokken, waardoor wij de volledige controle hebben over alle operationele aspecten. Zo kunnen wij gemakkelijk voldoen aan onze richtlijnen en lopen we geen risico op niet-naleving van de wet. Deze aanpak werkt goed voor wanneer we werken met LLM's met opensourcedatabase zoals Llama 2 of Falcon, met 7 tot 10 miljard parameters. In de toekomst zullen we ook grotere modellen kunnen ondersteunen.
Dat brengt ons meteen bij de tweede aanpak. Voor sommige complexe use cases kan het zijn dat we basismodellen nodig hebben die niet opensource zijn of die te groot zijn om in een eigen infrastructuur te kunnen worden uitgevoerd. In dergelijke gevallen gaan we op zoek naar een beheerde modeldienst die aan onze richtlijnen voldoet. LanguageWire gaat niet zomaar in zee met elke aanbieder van modellen. We willen er zeker van zijn dat de aanbieder onze strenge vereisten voor veiligheid en naleving ondersteunt. Een goed voorbeeld hiervan is de beheerde LLM-dienst van Google, PaLM 2. PaLM 2 is een omvangrijk en ingewikkeld model dat goed presteert in meertalige use cases, wat het erg interessant maakt voor onze sector. Google garandeert dat de infrastructuur zich in de EU bevindt, dat er geen gegevens worden opgeslagen, dat er volledige encryptie is en biedt aanpassingsopties met PEFT/LoRA (allemaal in vroege preview)! Een goede match en veilig te gebruiken voor onze klanten.
We kunnen besluiten dat het mogelijk is om LLM's op een veilige manier uit te voeren en tegelijkertijd te voldoen aan de nalevingsvoorschriften. Dat is niet eenvoudig, maar het technische team van LW heeft de nodige infrastructuur, beleidslijnen en software geïmplementeerd om dit mogelijk te maken. Bovendien zijn onze LLM-activiteiten volledig geïntegreerd in de andere delen van ons beveiligde tech-ecosysteem. Dit betekent dat LW zijn klanten het hoogste niveau van beveiliging en gegevensprivacy in de sector kan garanderen, zowel voor het volledige end-to-end proces als voor wanneer LLM's worden gebruikt in de toeleveringsketen.
Andere interessante artikelen
Jouw weg naar een krachtig, naadloos taalbeheer begint hier! Laat ons weten wat jij nodig hebt en wij bedenken de beste oplossing voor jouw onderneming.


