
 Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Los grandes modelos de lenguaje (LLM, por sus siglas en inglés) no gozan de buena fama en lo que respecta a la seguridad y privacidad de los datos. Puede que hayas oído hablar de la filtración de datos privados en ChatGPT; es decir, de los datos del cliente A que aparecen en las respuestas del chat del cliente B. Esto preocupa, con razón, a muchos usuarios de empresas. ¿Cómo podemos utilizar la tecnología de los LLM de forma segura y conforme a la legislación europea?
Los LLM no son inherentemente inseguros, esa es una buena noticia. Un gran modelo de lenguaje no empezará a filtrar automáticamente datos privados de forma intencionada. Estos riesgos los causa la forma en que el proveedor de servicios del modelo lo opera y gestiona. Los dos riesgos más importantes en cuanto a seguridad y privacidad de los datos en el contexto de un LLM son:
El modelo «filtra» datos privados o confidenciales del contexto de un cliente a otro. Esto sucede, por ejemplo, cuando el modelo de base compartida o el modelo de instrucciones se entrenan automáticamente con datos procedentes de los clientes. En ese caso, un mensaje del cliente B podría relacionarse con una estructura del modelo que cite datos textuales del cliente A. Otro tipo de filtraciones podrían deberse a una mala arquitectura técnica, como el uso de una caché genérica que no respeta el contexto del cliente.
Estos riesgos suelen estar relacionados con la forma en que un proveedor de modelos opera la infraestructura y cómo almacena los datos que los clientes envían al modelo. Si el proveedor simplemente recoge la información proporcionada por el cliente y almacena todo de forma indefinida (por ejemplo, para su uso en el entrenamiento de modelos), existe un riesgo considerable de que el proveedor almacene datos personales durante mucho tiempo. Esto podría provocar problemas relacionados con el RGPD si tenemos que eliminar datos personales de todos los sistemas y de los sistemas de los subcontratistas.
Te recuerdo que en este artículo del blog solo estamos analizando los riesgos relacionados con la privacidad y los datos. Otros riesgos, como las alucinaciones, el contenido dañino o la toxicidad, que están relacionados con las «tres H» (del inglés, útil, inofensivo, honesto) no los abordamos en esta publicación.
Comencemos con el riesgo de filtraciones de datos. Como ya vimos en nuestra entrada anterior del blog Grandes modelos de lenguaje y traducción automática: la era de la hiperpersonalización, ajustar el LLM con nuestros propios datos es una gran idea, ya que aumentará significativamente la calidad de la producción del LLM. Solo tenemos que estar seguros de que somos los únicos que podemos utilizar estas adaptaciones, lo que significa que no debemos personalizar una base compartida ni un modelo instruido con datos confidenciales o privados de nuestros clientes.
Como su nombre indica, los grandes modelos de lenguaje son muy grandes y sería prohibitivo personalizar un LLM completo para cada uno de nuestros clientes. Pero hay otras técnicas más eficientes.
En LanguageWire utilizamos la tecnología PEFT con LoRA y el aprendizaje de contexto, y estas técnicas nos permiten mantener un modelo de base neutro en lo referente al cliente y cargar las adaptaciones durante la ejecución o cuando se introduce el mensaje. De este modo, separamos los datos de los clientes en la esfera física y lógica. No hay posibilidad de que los datos del cliente A se filtren al cliente B: dependiendo de quién realice la solicitud, el modelo solo tiene acceso a los datos relevantes para ese cliente en concreto.
Esto se ilustra en la Figura 1.
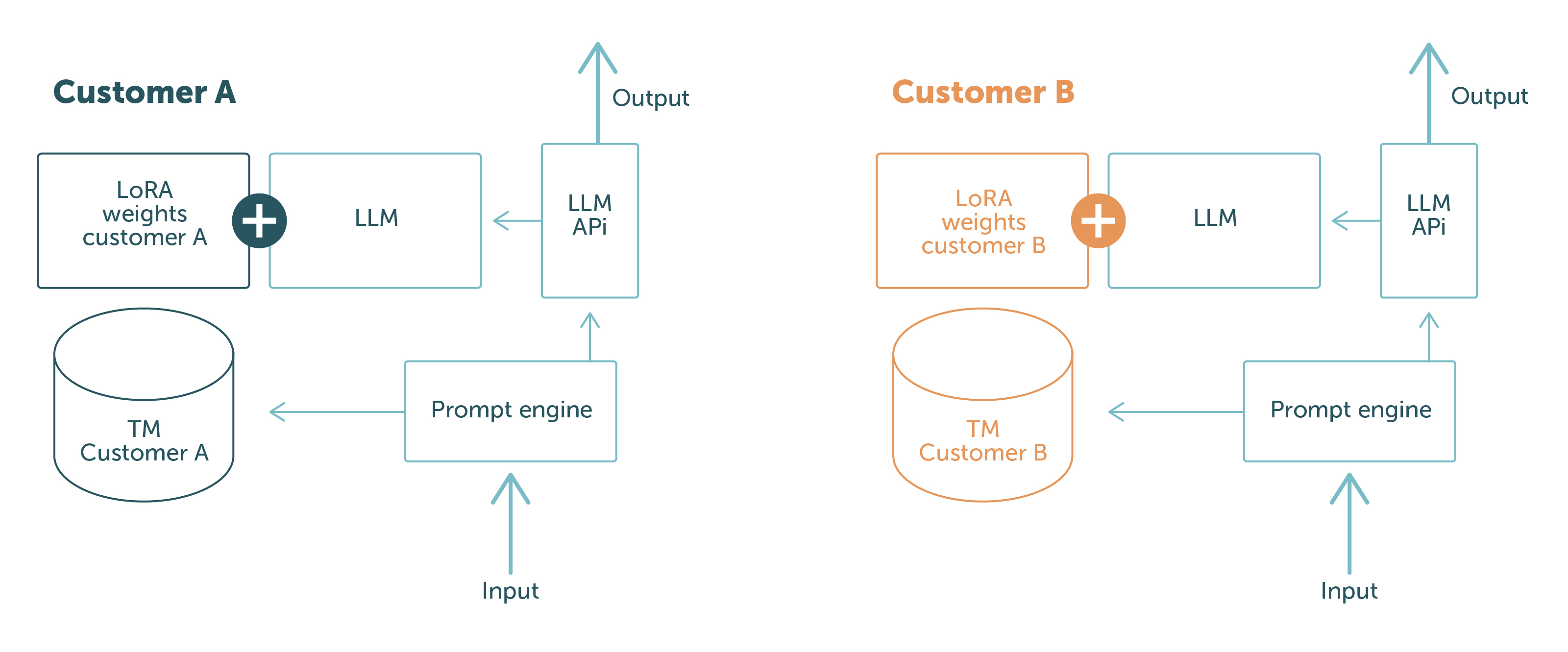
Las partes azules son los componentes del software y los datos que se intercambian entre las distintas solicitudes del cliente. Las partes de otros colores son específicas del cliente. Esto muestra claramente la separación de los datos de los clientes:
Con esta configuración, podemos garantizar a nuestros clientes que nunca divulgaremos datos de un cliente a otro. ¡Problema resuelto!
Para asegurarnos de no correr riesgos relacionados con el cumplimiento, el equipo de ingeniería de LanguageWire sigue un conjunto claro de directrices relacionadas con los LLM y otros modelos de IA:
Garantizamos el cumplimiento de estas directrices siendo muy cuidadosos con nuestras actividades y nuestra infraestructura. LanguageWire utiliza dos planteamientos para ejecutar los LLM.
El primero consiste en que el LLM lo operen por completo ingenieros de confiabilidad del sistema de LW e ingenieros de producto. Esto significa que nosotros mismos suministramos y configuramos todos los recursos de infraestructura necesarios, como GPU, redes, almacenamiento de modelos, contenedores, etc. No hay actores externos involucrados, lo que nos da un control total sobre todos los aspectos operativos. Este planteamiento facilita el ajuste a nuestras directrices para no correr riesgos de cumplimiento legal, y funciona bien en casos en los que utilizamos LLM de código abierto como Llama 2 o Falcon, con entre 7000 y 10 000 millones de parámetros. En el futuro, puede que también podamos ejecutar modelos más grandes.
Esto nos lleva al segundo planteamiento. En algunos casos complejos, puede que necesitemos modelos de base que no sean de código abierto o que sean demasiado grandes para ejecutarlos en una infraestructura autoaprovisionada. En ese caso, buscaremos un servicio de modelo administrado que se ajuste a nuestras directrices. LanguageWire es muy estricta en la selección de proveedores de modelos, ya que nos aseguramos de que el proveedor cumpla con nuestros requisitos estrictos de seguridad y cumplimiento. Un buen ejemplo es el servicio LLM de Google para PaLM 2. PaLM 2 es un modelo amplio y complejo que funciona bien en casos de uso multilingües, por lo que es muy interesante para nuestro sector. Google garantiza la localización de las infraestructuras en la UE, el almacenamiento nulo de datos, el cifrado completo y ofrece opciones de personalización con PEFT/LoRA (todo con una vista previa temprana). Una buena opción y de uso seguro para nuestros clientes.
Podemos concluir que es posible operar los LLM de una manera segura que también respete las normas de cumplimiento. Definitivamente, no es trivial hacerlo, pero el equipo de ingeniería de LW ha puesto en marcha la infraestructura, las políticas y el software necesarios para habilitar esta opción. Además, las operaciones de los LLM están totalmente integradas con las otras partes de nuestro ecosistema tecnológico seguro. Esto significa que LW puede garantizar a sus clientes el más alto nivel de seguridad y privacidad de datos del sector en procesos completos, y también cuando se utilizan LLM en la cadena de suministro.
Otros artículos de interés
Tu viaje hacia una experiencia en la gestión lingüística eficiente y sin complicaciones comienza aquí. Cuéntanos qué necesitas y te ofreceremos la solución perfecta adaptada a tu empresa.


