
 Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Wenn es um Datensicherheit und Datenschutz geht, haben große Sprachmodelle (LLMs) keinen guten Ruf. Sie haben bestimmt schon von der Offenlegung von privaten Daten in ChatGPT gehört. Da kann es vorkommen, dass die Daten von Kunde A in den Chat-Antworten bei Kunde B angezeigt werden. Vielen geschäftlichen Nutzern bereitet dies zu Recht Sorgen. Wie können wir sicherstellen, dass wir die LLM-Technologie auf sichere Weise und im Einklang mit den europäischen Gesetzen verwenden?
Die gute Nachricht ist, dass LLMs nicht per se unsicher sind. Ein großes Modell gibt nicht schon aufgrund seiner Konzeption automatisch private Daten preis. Diese Risiken werden durch die Art und Weise verursacht, wie ein Anbieter von LLM-Services das Modell handhabt und betreibt. Die beiden wichtigsten Risiken bei Datensicherheit und Datenschutz im Zusammenhang mit LLMs sind:
Das Modell legt private oder vertrauliche Daten aus einem Kundenkontext in einem anderen offen. Dies geschieht zum Beispiel, wenn das geteilte Basismodell oder das geschulte Modell automatisch mit den eingegebenen Daten von Kunden trainiert wird. Ein Prompt von Kunde B könnte in diesem Fall eine Modellierung mit wörtlich zitierten Daten von Kunde A auslösen. Andere Lecks können auf eine schlechte technische Architektur zurückzuführen sein, wie etwa die Verwendung eines generischen Caches, der den Kontext des Kunden nicht berücksichtigt.
Diese Risiken hängen in der Regel mit der Art und Weise zusammen, wie ein Modellanbieter die Infrastruktur betreibt und wie sie die Daten speichert, die die Kunden an das Modell senden. Nimmt der Anbieter lediglich den Kundeninput und speichert alles auf unbefristete Zeit (z. B. zum Trainieren des Modells), besteht ein erhebliches Risiko, dass der Anbieter personenbezogene Daten über einen längeren Zeitraum speichert. Dies kann zu Problemen in Bezug auf die DSGVO führen, etwa wenn wir personenbezogene Daten aus allen Systemen und Unterlieferantensystemen löschen müssen.
Bitte beachten Sie, dass wir in diesem Artikel nur auf die Risiken in Bezug auf Daten und den Datenschutz eingehen. Andere Risiken wie Halluzinationen, schädliche Inhalte, Toxizität usw., die im Zusammenhang mit dem Ziel der KI stehen, hilfreich, harmlos und ehrlich („helpful, harmless, honest“) zu sein, werden von diesem Beitrag nicht abgedeckt.
Beginnen wir mit dem Risiko von Datenlecks. Wie wir in unserem vorigen Blogbeitrag Große Sprachmodelle und maschinelle Übersetzung: Das Zeitalter der Hyperpersonalisierung erläutert haben, empfiehlt sich die Feinabstimmung des LLM mit Ihren eigenen Daten: Dadurch wird die Qualität der LLM-Ergebnisse erheblich erhöht. Sie müssen nur die Gewissheit haben, dass Sie die einzigen sind, die diese Anpassungen nutzen können. Das bedeutet, dass wir kein mit anderen geteiltes Basismodell oder trainiertes Modell mit vertraulichen oder privaten Kundendaten anpassen sollten!
Wie der Name schon sagt, sind die große Sprachmodelle äußerst umfangreich und es wäre extrem kostspielig, für jeden unserer Kunden ein vollständiges LLM zu erstellen. Aber es gibt andere, effizientere Verfahren.
Bei LanguageWire nutzen wir PEFT mit LoRA und kontextbezogenes Lernen. Mit diesen Verfahren können wir ein kundenneutrales Basismodell beibehalten und die Anpassungen zur Laufzeit oder während des Prompts laden. Auf diese Weise halten wir die Kundendaten auf physischer und logischer Ebene voneinander getrennt. Die Daten von Kunde A können nicht gegenüber Kunde B offengelegt werden: Abhängig davon, wer die Anfrage stellt, hat das Modell nur Zugriff auf die für den Kunden relevanten Daten.
Dies ist in Abb. 1 dargestellt.
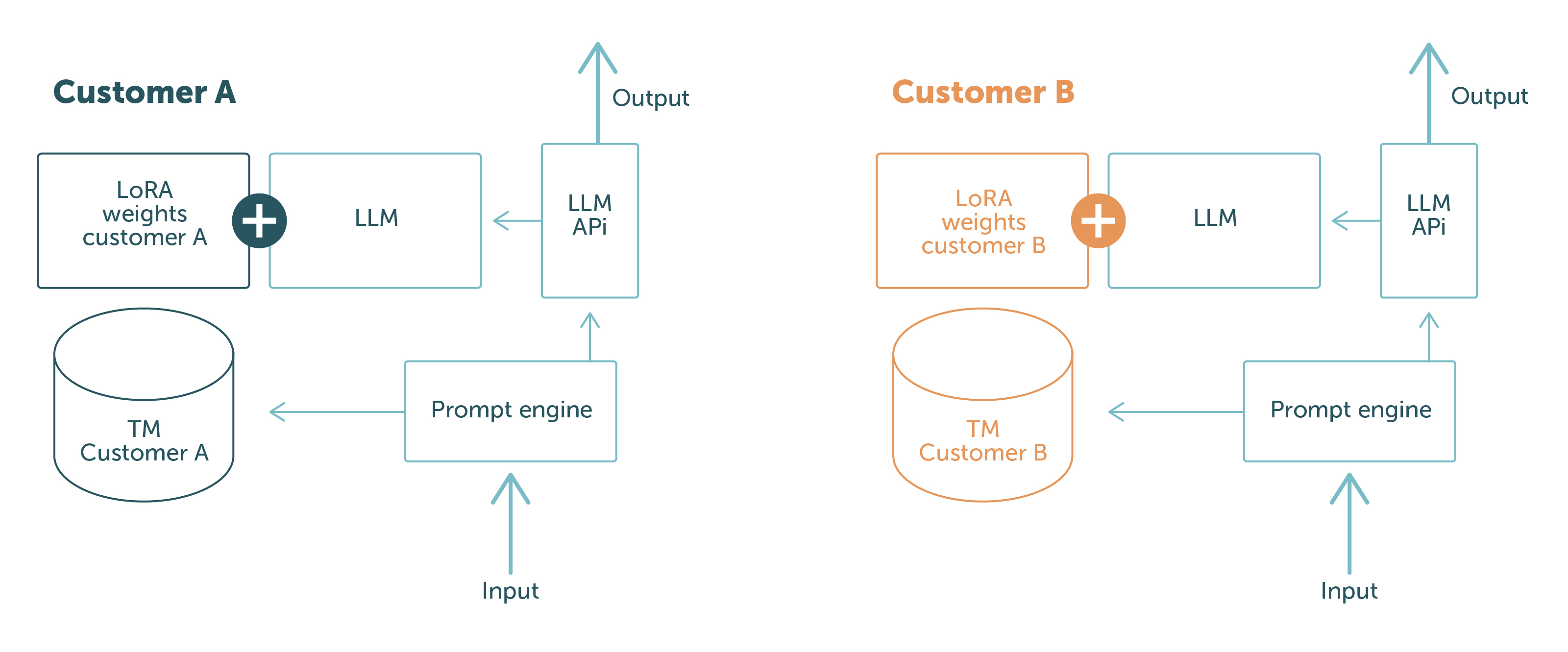
Die blauen Teile sind die Software-Komponenten und Daten, die zwischen verschiedenen Kundenanfragen ausgetauscht werden. Die Teile in anderen Farben sind kundenspezifisch. Dies zeigt deutlich die starke Trennung der Kundendaten:
Mit dieser Konfiguration können wir unseren Kunden garantieren, dass wir niemals Daten von einem Kunden gegnüber einem anderen offenlegen. Problem gelöst!
Um Compliance-Risiken zu vermeiden, befolgt das Engineering-Team von LanguageWire klare Richtlinien in Bezug auf LLMs und andere KI-Systeme:
Wir setzen diese Richtlinien durch, indem wir unseren Abläufen und unserer Infrastruktur höchste Aufmerksamkeit widmen. LanguageWire verwendet zwei Ansätze, um LLMse auszuführen.
Die erste Möglichkeit besteht darin, dass das LLM vollständig von LW System Reliability Engineers und Product Engineers bedient wird. Das bedeutet, dass wir alle notwendigen Infrastructure-Ressourcen wie GPUs, Netzwerke, Modellspeicher, Container usw. selbst bereitstellen und konfigurieren. Dabei sind keine Drittanbieter beteiligt, was uns die volle Kontrolle über alle betrieblichen Aspekte gibt. So können wir unsere Richtlinien leicht einhalten und Compliance-Risiken vermeiden. Dieser Ansatz eignet sich gut für Fälle, in denen wir Open-Source-Basismodelle wie Llama 2 oder Falcon mit 7 bis 10 Milliarden Parametern verwenden. In Zukunft können wir auch den Betrieb von größeren Modellen unterstützen.
Das bringt uns auch zu unserem zweiten Ansatz. Für einige komplizierte Anwendungsfälle brauchen wir möglicherweise Basismodelle, die keine Open-Source-Modelle oder zu groß sind, um in einer selbst bereitgestellten Infrastruktur betrieben zu werden. In diesem Fall suchen wir nach einem Managed Model, das unseren Richtlinien entspricht. LanguageWire ist bei der Auswahl der Modellanbieter sehr streng. Wir möchten sicherstellen, dass die Anbieter unsere strengen Sicherheits- und Compliance-Anforderungen erfüllt. Ein gutes Beispiel ist der Managed LLM Service von Google für PaLM 2. PaLM 2 ist ein umfangreiches und komplexes Modell, das in mehrsprachigen Anwendungsfällen gut funktioniert und daher für unsere Branche sehr interessant ist. Google garantiert, dass sich die Infrastruktur in der EU befindet, Null-Datenspeicherung, vollständige Verschlüsselung und bietet Anpassungsmöglichkeiten mit PEFT/LoRA (alles in Early Preview)! Das ist ein guter Ansatz, der für unsere Kunden sicher in der Anwendung ist.
Zusammenfassend können wir sagen, dass es möglich ist, LLMs auf eine sichere Weise zu betreiben, die auch die Compliance-Vorschriften berücksichtigt. Das ist alles andere als ein Kinderspiel, aber das Engineering-Team von LW hat die Infrastruktur, Richtlinien und Software eingeführt, um dies zu ermöglichen. Darüber hinaus ist der LLM-Betrieb vollständig in die anderen Teile unseres sicheren Technologie-Ökosystems integriert. Das bedeutet, dass LW unseren Kunden ein Höchstmaß an Datensicherheit und Datenschutz für den gesamten End-to-End-Prozess gewährleisten kann – auch dann, wenn große Sprachmodelle in der Lieferkette eingesetzt werden.
Andere Artikel, die Sie interessieren könnten
Ihr Weg zu einem leistungsstarken, integrierten Sprachmanagement beginnt hier! Nennen Sie uns Ihre Anforderungen und wir finden die optimale Lösung für Ihr Unternehmen.


