
 Roeland Hofkens, Chief Product & Technology Officer, LanguageWire
Roeland Hofkens, Chief Product & Technology Officer, LanguageWire
Les grands modèles de langage (LLM) n’ont pas bonne réputation en matière de sécurité et de confidentialité des données. Vous avez peut-être entendu parler de fuites de données confidentielles dans ChatGPT, c’est-à-dire des données du client A apparaissant dans les réponses au chat du client B. Cela inquiète à juste titre de nombreux utilisateurs professionnels. Comment pouvons-nous nous assurer que nous utilisons la technologie LLM de manière sûre et conforme à la législation européenne ?
La bonne nouvelle, c’est que les LLM ne sont pas intrinsèquement dangereux. Un grand modèle ne commencera pas automatiquement à laisser filtrer des données privées. Ces risques sont tous dus à la façon dont un fournisseur de modèles gère et exploite le modèle. Les deux risques les plus importants en matière de sécurité et de confidentialité des données dans un contexte de LLM sont les suivants :
Le modèle fait « fuiter » des données privées ou confidentielles d’un client à un autre. Cela se produit, par exemple, lorsque le modèle de base partagé ou le modèle adapté aux instructions est automatiquement formé avec des données d’entrée provenant des clients. Dans ce cas, une invite du client B pourrait entraîner la réalisation d’un modèle citant les données exactes du client A. D’autres fuites peuvent être causées par une mauvaise architecture technique, comme l’utilisation d’un cache général qui ne respecte pas le contexte du client.
Ces risques sont généralement liés à la manière dont un fournisseur de modèles exploite l’infrastructure et stocke les données que les clients envoient au modèle. Si le fournisseur se contente de recueillir les données du client et de les stocker indéfiniment (par exemple, pour la formation modèle), il existe un risque important que celui-ci stocke des données à caractère personnel pendant une longue période. Cela peut entraîner des problèmes de RGPD si nous devons supprimer les données à caractère personnel de tous les systèmes et des systèmes des sous-traitants.
Veuillez noter que dans cet article, nous n’examinons que les risques en matière de données et de confidentialité. D’autres risques tels que les hallucinations, le contenu nocif, la toxicité, etc. qui sont liés à la pertinence, la dangerosité ou l’honnêteté n’entrent pas dans le cadre de cet article.
Commençons par le risque de fuite de données. Comme nous l’avons expliqué dans notre article précédent intitulé Grands modèles de langage et traduction automatique : l’ère de l’hyper-personnalisation, le réglage du LLM avec vos propres données est une excellente idée : cela augmentera considérablement la qualité des résultats du LLM. Vous devez simplement vous assurer que vous êtes le seul à pouvoir utiliser ces personnalisations, ce qui signifie qu’il ne faut pas personnaliser une base partagée ou un modèle formé avec des données client confidentielles ou privées !
Comme leur nom l’indique, les grands modèles de langage sont vraiment volumineux et il serait extrêmement coûteux de personnaliser un LLM complet pour chacun de nos clients. Mais il existe d’autres techniques plus efficaces.
Chez LanguageWire, nous utilisons PEFT avec LoRA et l’apprentissage contextuel. Grâce à ces techniques, nous pouvons conserver un modèle de base neutre pour le client et charger les personnalisations au moment de l’exécution ou dans l’invite. Ainsi, nous séparons les données des clients sur le plan physique et logique. Il n’y a aucun risque que les données du client A soient divulguées au client B : en fonction de la personne effectuant la demande, le modèle n’a accès qu’aux données pertinentes pour le client.
Ceci est illustré dans la Figure 1.
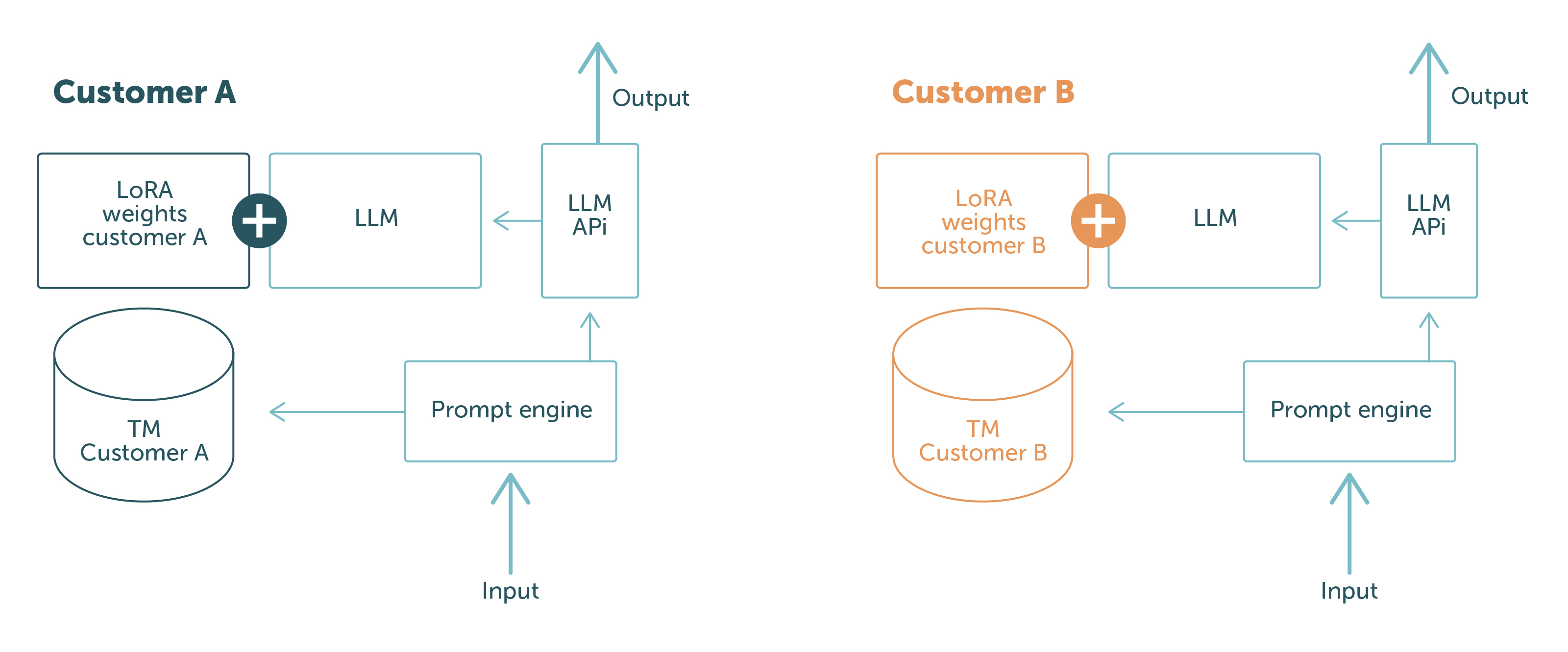
Les parties en bleu sont les composants logiciels et les données qui sont partagées entre les différentes demandes des clients. Les parties dans d’autres couleurs sont spécifiques au client. Cela montre clairement la séparation nette des données clients :
Grâce à ce système, nous pouvons garantir à nos clients que nous n’exposerons jamais les données d’un client à un autre. Problème résolu !
Pour éviter tout risque de non-conformité, l’équipe d’ingénieurs de LanguageWire suit un ensemble de directives claires relatives aux LLM et autres modèles d’IA :
Nous appliquons ces directives en faisant très attention à nos opérations et à notre infrastructure. LanguageWire utilise deux approches pour gérer les LLM.
La première consiste à faire en sorte que le LLM soit entièrement géré par les ingénieurs en fiabilité des systèmes et les ingénieurs produits de LW. Cela signifie que nous fournissons et configurons nous-mêmes toutes les ressources infrastructurelles nécessaires, telles que les GPU, le réseau, le stockage de modèles, les conteneurs, etc. Aucun acteur tiers n’est impliqué, ce qui nous donne un contrôle total sur tous les aspects opérationnels. Cela facilite le respect de nos directives et nous évite d’être confrontés à des risques juridiques en matière de conformité. Cette approche fonctionne bien dans les cas où nous utilisons des LLM de base open source comme Llama 2 ou Falcon avec 7 à 10 milliards de paramètres. À l’avenir, nous pourrons également prendre en charge l’exécution de modèles plus grands.
Cela nous amène à la deuxième approche. Pour certains cas d’utilisation complexes, nous pouvons avoir besoin de modèles de base qui ne sont pas open source ou qui sont trop volumineux pour fonctionner dans une infrastructure auto-provisionnée. Dans ce cas, nous chercherons un service de modèle géré conforme à nos directives. LanguageWire est très stricte dans la sélection des fournisseurs de modèles. Nous voulons nous assurer que le fournisseur respecte nos exigences strictes en matière de sécurité et de conformité. Le service LLM géré de Google pour PaLM 2 en est un bon exemple. PaLM 2 est un modèle volumineux et complexe qui fonctionne bien dans les cas d’utilisation multilingue, il est donc très intéressant pour notre secteur. Google garantit la localité de l’infrastructure de l’UE, l’absence de stockage de données, le chiffrement complet et offre des options de personnalisation avec PEFT/LoRA (le tout en avant-première) ! Un bon choix et une utilisation sûre pour nos clients.
Nous pouvons en conclure qu’il est possible d’exploiter les LLM de manière sécurisée tout en respectant les règles de conformité. Cela n’est certainement pas simple, mais l’équipe d’ingénieurs de LW a mis en place l’infrastructure, les politiques et les logiciels nécessaires à cette fin. De plus, les services du LLM sont entièrement intégrés aux autres parties de notre écosystème technologique sécurisé. Cela signifie que LW peut garantir à ses clients le plus haut niveau de sécurité et de confidentialité des données du secteur pour l’ensemble du processus de bout en bout, y compris lorsque les LLM sont utilisés dans la chaîne de livraison.
Autres articles intéressants
Ouvrez-vous la voie vers une gestion efficace et harmonieuse de vos contenus en différentes langues ! Faites-nous part de vos besoins et nous créerons la solution sur mesure idéale pour votre entreprise.


