
 Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Store språkmodeller (LLM-er) har ikke så godt omdømme når det gjelder datasikkerhet og personvern. Du har kanskje hørt om lekkede personopplysninger i ChatGPT, altså opplysninger fra kunde A som dukker opp i chatten hos kunde B. Dette bekymrer med rette mange bedriftsbrukere. Hvordan kan vi sikre at vi bruker LLM-teknologi på en sikker måte og som er i samsvar med europeisk lov?
Den gode nyheten er at selve LLM-ene ikke utgjør en sikkerhetstrussel. En stor modell vil ikke automatisk begynne å lekke personopplysninger. Slike risikoer skyldes nemlig måten leverandøren av modelltjenestene håndterer og driver modellen på. De to viktigste risikoene for datasikkerhet og personvern i en LLM-kontekst er:
Modellen «lekker» personopplysninger eller konfidensielle data fra én kunde til en annen. Dette skjer for eksempel når den delte basismodellen eller instruksjonstilpassede modellen læres opp automatisk med inndata fra kunder. Her kan en ledetekst fra kunde B føre til at en modell fullføres med ordrette opplysninger for kunde A. Andre lekkasjer kan skyldes dårlig teknisk arkitektur, for eksempel bruk av en generisk hurtigbuffer som ikke tar hensyn til kundekontekst.
Disse risikoene er vanligvis knyttet til måten en modelleverandør driver infrastrukturen på og hvordan leverandøren lagrer dataene kundene sender til modellen. Hvis leverandøren bare tar innspill fra kunden og lagrer alt på ubestemt tid (f.eks. for å bruke til modellopplæring), er det en betydelig risiko for at leverandøren lagrer personopplysninger over lang tid. Dette kan føre til GDPR-problemer hvis vi må fjerne personopplysninger fra egne systemer og underleverandørers systemer.
Husk at vi i denne bloggartikkelen bare ser på risikoer knyttet til datasikkerhet og personvern. Andre risikoer, slik som hallusinasjoner og skadelig eller negativt innhold knyttet til verdiordene hjelpsom, ufarlig og ærlig, omtales ikke i dette innlegget.
La oss starte med risikoen for datalekkasje. Som vi forklarte i det forrige blogginnlegget Store språkmodeller og maskinoversettelse: Hyperpersonaliseringens tidsalder, er det lurt å finjustere LLM-en med egne data: Det vil nemlig øke kvaliteten på LLM-utdataene betydelig. Du må bare være sikker på at du er den eneste som kan bruke disse tilpasningene, noe som betyr at vi ikke skal tilpasse en delt database eller instruert modell med konfidensielle eller personlige kundedata!
Som navnet antyder er store språkmodeller veldig store, og det ville være uhyre dyrt å tilpasse en komplett LLM for hver av kundene våre. Men det finnes andre, mer effektive metoder.
Hos LanguageWire bruker vi PEFT med LoRA og kontekstuell læring, og ved hjelp av disse teknikkene kan vi opprettholde en kundenøytral basismodell og laste inn tilpasningene i sanntid eller i ledeteksten. På denne måten holder vi kundedata adskilt, både fysisk og logisk. Det er ingen mulighet for at data fra kunde A kan lekkes til kunde B: Avhengig av hvem som sender forespørselen, har modellen bare tilgang til data som er relevante for kunden.
Dette er illustrert i figur 1.
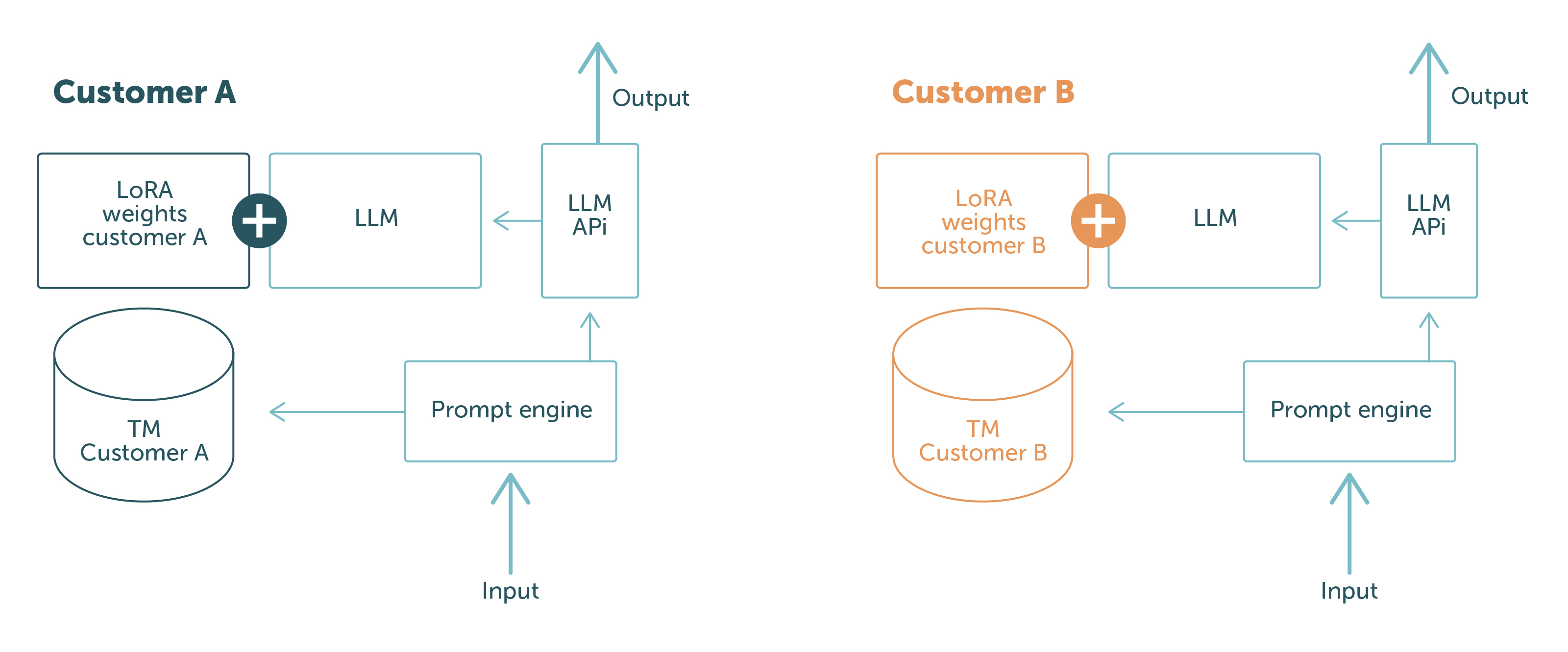
De blå delene er programvarekomponenter og data som deles mellom ulike kunder. Delene i andre farger er kundespesifikke. Dette viser tydelig at kundedata holdes helt atskilt:
Med dette oppsettet kan vi garantere kundene våre at vi aldri vil eksponere data fra én kunde til en annen. Problemet er dermed løst!
For å sikre at vi ikke utsettes for samsvarsrisikoer, følger LanguageWires ingeniørteam et tydelig sett med retningslinjer knyttet til LLM-er og andre KI-modeller:
Vi følger disse retningslinjene ved å være svært forsiktige med driften og infrastrukturen vår. LanguageWire har innført to forutsetninger for kjøring av LLM-er.
Den første forutsetningen er at LLM-en drives i sin helhet av LW System Reliability Engineers og Product Engineers. Det betyr at vi sørger selv for å klargjøre og konfigurere alle nødvendige infrastrukturressurser som GPU-er, nettverk, modellagring, containere osv. Det er ingen tredjepartsaktører involvert, noe som gir oss full kontroll over alle driftsmessige aspekter. Dette gjør det enkelt å følge retningslinjene våre, slik at vi ikke risikerer brudd på det juridiske samsvaret. Denne forutsetningen fungerer godt i tilfeller der vi bruker åpen kildekode-baserte LLM-er som Llama 2 eller Falcon med 7 til 10 milliarder parametere. I fremtiden vil vi også kunne støtte kjøring av større modeller.
Det bringer oss også til den andre forutsetningen. I noen komplekse tilfeller kan vi trenge basismodeller som ikke er åpen kildekode eller som er for store til å kjøres i en selvforsynt infrastruktur. I så fall vil vi se etter en administrert modelltjeneste som overholder retningslinjene våre. LanguageWire er svært strenge når det gjelder valg av modelleverandør. Vi ønsker å sikre at leverandøren støtter de strenge kravene vi stiller til sikkerhet og samsvar. Et godt eksempel er Googles administrerte LLM-tjeneste for PaLM 2. PaLM 2 er en stor og kompleks modell som fungerer godt i flerspråklige tilfeller, så den er svært interessant innen vår bransje. Google garanterer infrastruktur i EU, null datalagring, full kryptering og tilpasningsmuligheter med PEFT/LoRA (alle i tidlig forhåndsvisning)! En god match og trygg å bruke for kundene våre.
Vi kan konkludere med at det er mulig å drive LLM-er på en sikker måte som også er i tråd med kravene til samsvar. Dette er helt klart ingen enkel oppgave, men LWs teknikerteam har innført infrastrukturen, retningslinjene og programvaren som muliggjør dette. I tillegg er LLM-operasjonene fullt integrert med de andre delene av vårt sikre teknologiske økosystem. Dette betyr at LW kan garantere kundene våre det høyeste nivået av sikkerhet og personvern i bransjen for hele end-to-end-prosessen, og også når LLM-er brukes i leveransekjeden.
Andre nyttige artikler
Din reise til kraftig, sømløs språkstyring starter her! Fortell oss om behovene dine, så skreddersyr vi en perfekt løsning for bedriften din.


