
 Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Large Language Models (LLM'er) har ikke et godt ry, når det kommer til datasikkerhed og beskyttelse af personoplysninger. Du har måske hørt, at der blev lækket private oplysninger i ChatGPT, dvs. oplysninger fra kunde A dukkede op i chatsvar hos kunde B – dette bekymrer med rette mange virksomheder. Hvordan kan vi sikre, at vi bruger LLM-teknologi på en sikker måde, der samtidig overholder den europæiske lovgivning?
Den gode nyhed er, at LLM'er i sig selv ikke er usikre. Baseret på designet vil en Large Language Model ikke automatisk begynde at lække private data. Risikoen for dette skyldes udelukkende den måde, hvorpå en modeltjenesteudbyder håndterer og driver modellen. De to vigtigste datasikkerheds- og databeskyttelsesrisici i LLM-sammenhæng er:
Modellen "lækker" private eller fortrolige data fra den ene kundekontekst til den anden. Det sker f.eks., når en delt basismodel eller instruktionsjusteret model automatisk trænes med inputdata fra kunder. I sådanne tilfælde kan en prompt fra kunde B udløse en modelfuldførelse, der citerer ordrette data fra kunde A. Andre læk kan skyldes en dårlig teknisk arkitektur, f.eks. brug af en generisk cache, der ikke tager hensyn til kundens kontekst.
Disse risici er normalt relateret til den måde, hvorpå en modeludbyder driver infrastrukturen, og hvordan den lagrer de data, som kunderne sender til modellen. Hvis udbyderen blot tager kundernes input og lagrer alt på ubestemt tid (f.eks. til brug til træning af modellen), er der en betydelig risiko for, at udbyderen opbevarer personlige data over en længere periode. Det kan føre til problemer i forbindelse med GPDR, hvis det er nødvendigt at slette personoplysninger fra alle systemer og underleverandørsystemer.
Bemærk, at vi i dette blogindlæg kun tager et kig på risici for data og personoplysninger. Andre risici som hallucinationer, skadeligt indhold, toksicitet osv. der er relateret til det, man på engelsk ville kalde "the three H's" (hjælpsom, harmløs, ærlig), er ikke omfattet af dette indlæg.
Lad os starte med risikoen for datalæk. Som vi fortalte om i vores tidligere blogindlæg Large Language Models og maskinoversættelse: Hyperpersonaliseringens æra, er det en god idé at finjustere LLM'en med dine egne data: Det vil øge kvaliteten af LLM-outputtet betydeligt. Du skal blot være sikker på, at du er den eneste, der kan bruge disse tilpasninger, hvilket betyder, at du ikke bør skræddersy en delt basis- eller instrueret model med fortrolige eller private kundedata.
Som navnet antyder, er Large Language Models rigtig store, og det ville være ekstremt dyrt at skræddersy en komplet LLM til hver enkelt af vores kunder. Men der findes andre, mere effektive teknikker.
Hos LanguageWire bruger vi PEFT med LoRA og kontekstbaseret læring, og ved hjælp af disse teknikker kan vi have en kundeneutral basismodel og indlæse tilpasningerne på run-time eller i prompten. På den måde holder vi kundedata adskilt på det fysiske og logiske niveau. Der er ingen risiko for, at dataene fra kunde A kan blive lækket til kunde B: Afhængigt af, hvem der foretager forespørgslen, har modellen kun adgang til de data, der er relevante for kunden.
Dette er illustreret i figur 1.
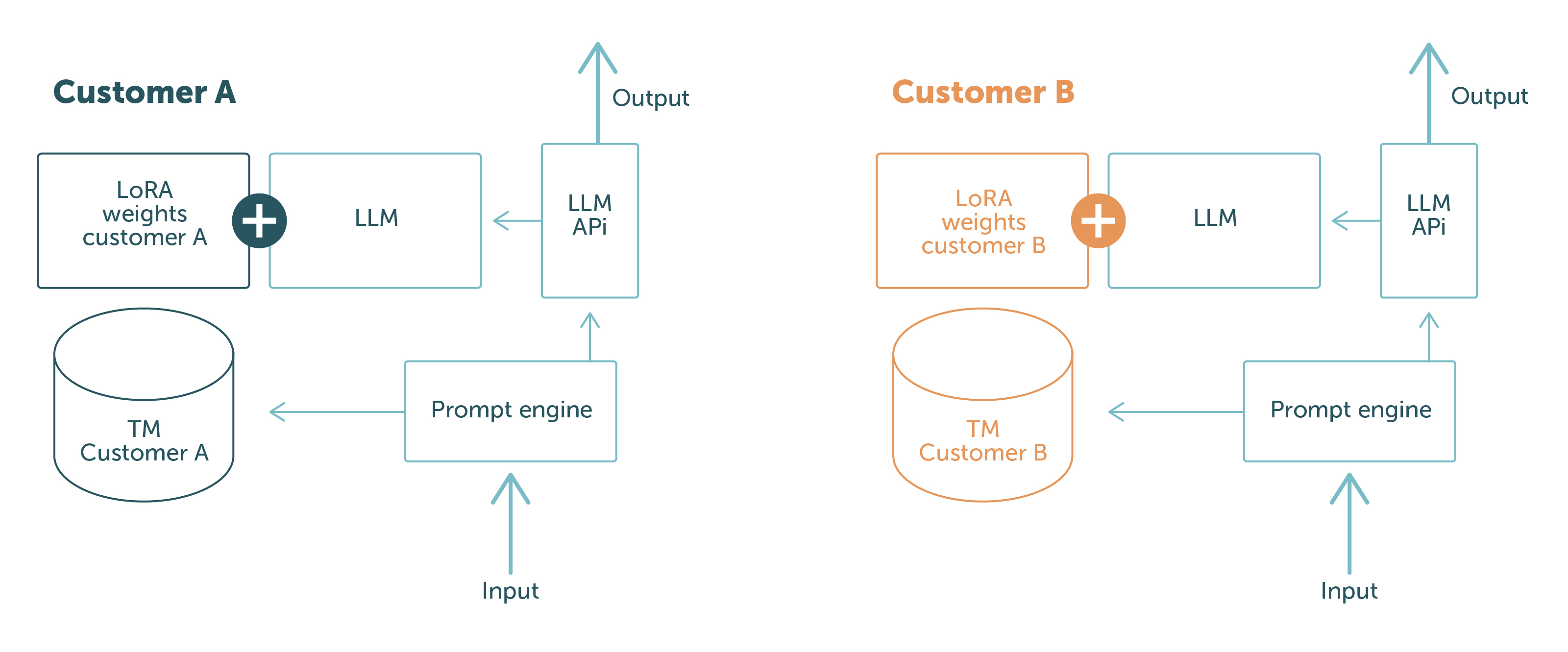
De blå dele er de softwarekomponenter og data, der deles mellem forskellige kundeforespørgsler. Delene i andre farver er kundespecifikke. Det viser tydeligt den solide adskillelse af kundedata:
Med dette setup kan vi garantere vores kunder, at vi aldrig vil eksponere data fra en kunde for en anden. Problemet er løst!
For at sikre, at vi ikke løber ind i problemer i forbindelse med compliance, følger LanguageWires engineering-team en række klare retningslinjer for LLM'er og andre AI-modeller:
Vi håndhæver disse retningslinjer ved at være meget omhyggelige med vores drift og infrastruktur. LanguageWire bruger to tilgange til at køre LLM'er.
Den første måde er, at LLM'en drives fuldt ud af LanguageWires System Reliability Engineers og Product Engineers. Det betyder, at vi selv stiller alle nødvendige infrastrukturressourcer som GPU'er, netværk, modellagring, containere osv. til rådighed og konfigurerer dem. Der er ingen tredjepartsaktører involveret, hvilket giver os fuld kontrol over alle driftsmæssige aspekter. Det gør det nemt at overholde vores retningslinjer, så vi ikke løber ind i problemer med compliance. Denne tilgang fungerer godt i tilfælde, hvor vi bruger open source-baserede LLM'er som Llama 2 eller Falcon med 7 til 10 milliarder parametre. I fremtiden vil vi måske også kunne understøtte kørsel af større modeller.
Det bringer os også videre til den anden tilgang. Ved nogle komplicerede use cases kan vi have brug for basismodeller, der ikke er open source, eller som er for store til at køre i en selvforsynende infrastruktur. I sådanne tilfælde vil vi søge efter en managed model-tjeneste, der overholder vores retningslinjer. LanguageWire er meget omhyggelig med udvælgelsen af modelleverandører. Vi ønsker at sikre, at leverandøren understøtter vores strenge krav til sikkerhed og compliance. Et godt eksempel er managed LLM-tjenesten fra Google for PaLM 2. PaLM 2 er en stor og kompleks model, der fungerer godt i flersprogede brugsscenarier, så den er meget interessant for vores branche. Google garanterer EU-infrastrukturens lokalitet, nul datalagring, fuld kryptering og tilbyder tilpasningsmuligheder med PEFT/LoRA (alt sammen i en tidlig forhåndsvisning)! Et godt match og sikker at bruge for vores kunder.
Vi kan konkludere, at det er muligt at drive LLM'er på en sikker måde, der også overholder diverse forordninger ifm. compliance. Det er helt sikkert ikke uden betydning, men LanguageWires engineering-team har implementeret infrastrukturen, politikkerne og softwaren, der gør det muligt. Derudover er driften af LLM'er fuldt integreret med de andre dele af vores sikre teknologiske økosystem. Det betyder, at LanguageWire kan garantere vores kunder det højeste niveau af sikkerhed og databeskyttelse i branchen – i hele processen fra start til slut, og også når LLM'er anvendes i leveringskæden.
Andre relevante artikler
Jeres rejse mod en effektiv og strømlinet håndtering af indhold på tværs af mange sprog starter her! Fortæl os om jeres behov, så skræddersyr vi den perfekte løsning til din virksomhed.


