
 Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Stora språkmodeller (LLM:er) har inget gott rykte när det gäller datasäkerhet och integritetsskydd. Kanske har du hört talas om att personuppgifter läcks i ChatGPT, dvs. att data från kund A visas i chattsvar hos kund B. Detta är något som med rätta oroar många företagsanvändare. Hur kan vi säkerställa att vi använder LLM-teknologi på ett säkert sätt, samt i enlighet med kraven i europeisk lagstiftning?
Den goda nyheten är att LLM:er inte är osäkra i sig, och de är inte designade för att läcka personuppgifter. Alla sådana risker orsakas av det sätt som leverantören av LLM-tjänsten hanterar och använder modellen. De två främsta riskerna för datasäkerhet och integritetsskydd i en LLM-kontext är följande:
Modellen ”läcker” privat eller konfidentiell information från en kundkontext till en annan. Detta händer till exempel när den delade basmodellen eller instruktionsjusterade LLM:en tränas automatiskt med indata från kunder. Här kan en prompt från kund B utlösa en modellkomplettering som ordagrant citerar data från kund A. Andra läckor kan orsakas av dålig arkitektur, till exempel användning av en generisk cache som inte respekterar kundkontext.
Riskerna i detta avseende gäller som regel hur leverantören av LLM-tjänsten använder infrastrukturen och hur man lagrar de data som kunderna skickar till modellen. Om leverantören helt enkelt tar kundens input och lagrar allt på obestämd tid (t.ex. för att använda vid modellträning) föreligger en avsevärd risk att leverantören lagrar personuppgifter under lång tid. Detta kan leda till GDPR-problem eftersom personuppgifter måste avlägsnas från alla system och underleverantörssystem.
Observera att vi i den här bloggartikeln endast tar upp risker för datasäkerhet och integritetsskydd. Det här inlägget omfattar inte andra risker som hallucinationer, skadligt innehåll, toxicitet osv. som är relaterat till ”de tre H:na” (helpful, harmless, honest).
Låt oss börja med risken för dataläckage. Som vi förklarade i vårt tidigare blogginlägg Stora språkmodeller och maskinöversättning: Hyperpersonaliseringens tidevarv är här är det en god idé att finjustera din LLM med dina egna data eftersom det avsevärt kommer att öka kvaliteten på LLM-resultatet. Du måste bara vara säker på att du är den enda som kan använda dessa anpassningar, vilket innebär att vi inte får anpassa en delad bas eller instruktionsjusterad modell med konfidentiella eller privata kunddata!
Som namnet antyder är stora språkmodeller väldigt stora och att specialanpassa en komplett LLM för var och en av våra kunder skulle vara enormt kostsamt. Men det finns andra, effektivare tekniker.
På LanguageWire använder vi PEFT med LoRA och kontextbaserad inlärning och med hjälp av dessa tekniker kan vi behålla en kundneutral basmodell och importera anpassningarna vid körning eller i prompten. På så vis håller vi kunddata åtskilda på fysisk och logisk nivå. Det finns ingen risk för att data om kund A kan läckas till kund B: beroende på vem som gör förfrågan har modellen endast tillgång till de data som är relevanta för kunden.
Detta framgår av bild 1.
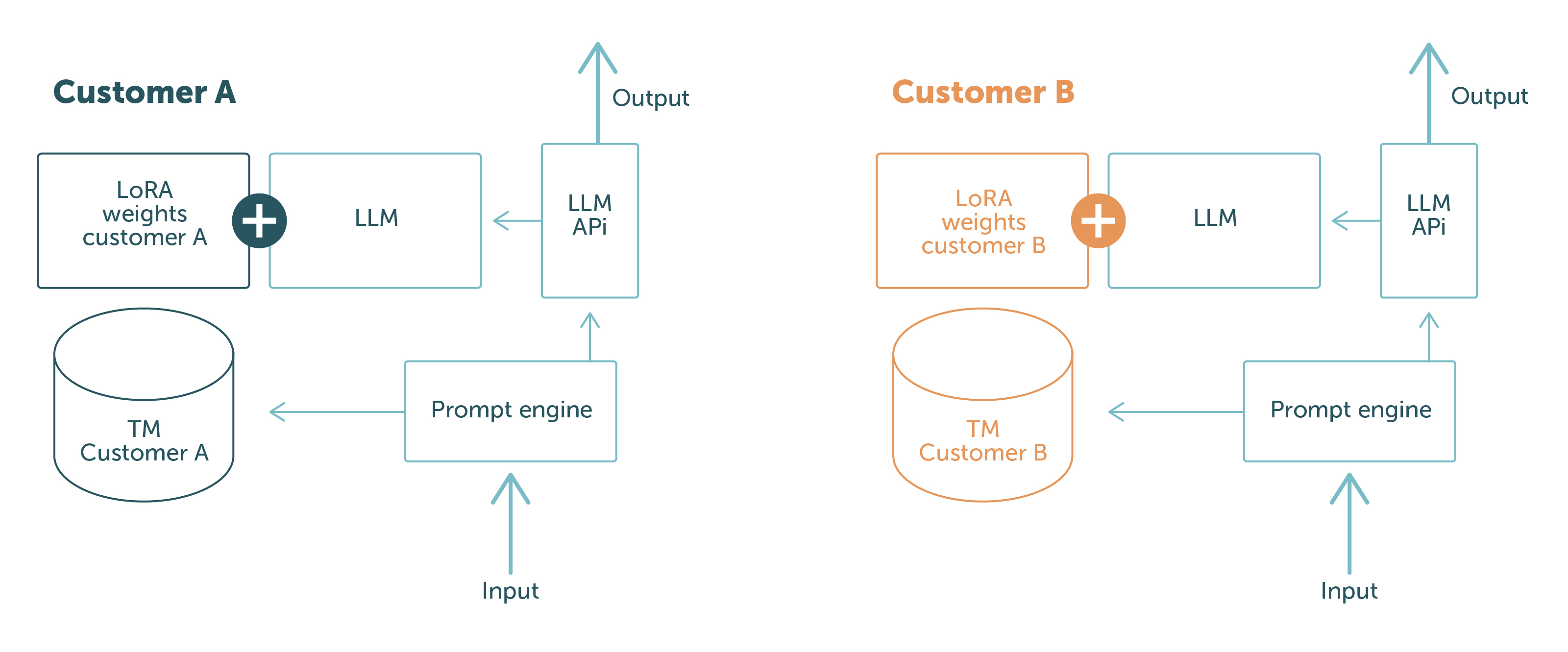
De blå delarna är de programvarukomponenter och data som delas mellan olika kundförfrågningar. Delarna i andra färger är kundspecifika. Här framgår den starka åtskillnaden av kunddata tydligt:
Med den här konfigurationen kan vi garantera våra kunder att vi aldrig kommer att exponera data från en kund till en annan. Problemet är löst!
För att säkerställa att vi inte råkar ut för efterlevnadsrisker följer LanguageWires team av tekniker en uppsättning tydliga riktlinjer relaterade till LLM:er och andra AI-modeller:
Vi följer dessa riktlinjer genom att vara mycket försiktiga när det gäller vår drift och infrastruktur. LanguageWire använder två metoder för att köra LLM:er.
Den första metoden är att LLM:en drivs helt och hållet av LanguageWires System Reliability Engineers och Product Engineers. Det innebär att vi själva tillhandahåller och konfigurerar alla erforderliga infrastrukturresurser som GPU:er, nätverk, modellagring, containrar osv. Genom att inte involvera några tredjepartsaktörer får vi full kontroll över alla driftsaspekter. Det gör det enkelt att följa våra riktlinjer så att vi inte riskerar att råka ut några efterlevnadsrisker i förhållande till gällande lagstiftning. Denna metod fungerar bra i de fall då vi använder LLM:er med öppen källkod som Llama 2 eller Falcon med 7 till 10 miljarder parametrar. I framtiden kan vi även komma att ha stöd för körning av större modeller.
Vilket leder oss till metod nummer två. I vissa komplexa användningsfall kan vi behöva basmodeller som inte har öppen källkod eller som är för stora för att köras i en egenutvecklad infrastruktur. I dessa fall försöker vi hitta en tjänsteleverantör som hanterar modellen och följer våra riktlinjer. LanguageWire är mycket strikt när det gäller valet av tjänsteleverantörer. Vi vill säkerställa att leverantören stödjer våra stränga säkerhets- och efterlevnadskrav. Ett bra exempel är Googles LLM-tjänst PaLM 2. PaLM 2 är en stor och komplex modell som fungerar bra i flerspråkiga användningsfall, vilket gör den mycket intressant för vår bransch. Google garanterar lokalisering av infrastruktur inom EU, noll datalagring, fullständig kryptering och erbjuder anpassningsmöjligheter med PEFT/LoRA (allt i tidig förhandsgranskning)! Det passar oss utmärkt och är säkert att använda för våra kunder.
Vi kan slå fast det är möjligt att driva LLM:er på ett säkert sätt som också respekterar efterlevnad av gällande lagar. Att göra det är definitivt ingen småsak, men LanguageWires team av tekniker har implementerat infrastrukturen, policyerna och programvaran som krävs för att möjliggöra detta. LLM-verksamheten är dessutom helt integrerad med andra delar av vårt säkra tekniska ekosystem. Det innebär att vi på LanguageWire kan garantera våra kunder den högsta nivån av datasäkerhet och integritetsskydd för hela processen, även när en LLM används i leveranskedjan.
Andra intressanta artiklar
Din resa mot en kraftfull, sömlös och enkel lösning för att skapa flerspråkigt innehåll börjar här! Berätta om dina behov så skräddarsyr vi den perfekta lösningen för ditt företag.


