
 Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Large Language Models (LLM) har taget verden med storm.
Nogle af disse modeller, som f.eks. OpenAI's GPT-4 og Google's PaLM2, er blevet oplært i et flersproget datasæt og bør – i det mindste i teorien – også kunne udføre maskinoversættelse.
Men er det virkelig tilfældet? Hvordan åbner vi op for det fulde potentiale ved Large Language Models til maskinoversættelse? I denne dybdegående tekniske analyse ser vi på, hvordan LLM'er fungerer i forbindelse med maskinoversættelse, og hvordan de kan integreres i et oversættelsessystem (TMS).
De fleste af de nuværende kommercielle maskinoversættelsesværktøjer såsom Google Translate er baseret på neurale modeller med en transformerarkitektur. Disse modeller er specialbygget til én opgave: maskinoversættelse. Som sådan klarer de sig allerede rigtig godt i de opgaver, der er nødvendige for at oversætte generisk indhold. Men i mere specialiserede sammenhænge finder de måske ikke frem til de rette ord, eller stilen er ikke helt optimal.
Derfor er det en god idé at skræddersy disse modeller med flere data om din virksomhed ved at oplære dem i at genkende dine personlige termer og sætninger. Modellen "lærer" at bruge din virksomheds tone of voice og terminologi ved hjælp af forskellige tilpasningsmetoder, hvilket giver et bedre maskinoversættelsesresultat
Large Language Models er normalt også baseret på transformerarkitektur. Men i forhold til NMT-modellerne (neural maskinoversættelse), som vi kom ind på i det foregående afsnit, er de trænet i meget større tekststykker og har flere modelparametre. LLM'er indeholder milliarder af parametre mod få hundrede millioner i tosprogede NMT-modeller. Det gør LLM-modellerne mere fleksible og "intelligente", når det drejer sig om at fortolke brugervejledninger eller "prompts". Den nye teknologi giver mange nye muligheder i forhold til modeltilpasning med virksomhedsdata. Og fordi den tilgang er så effektiv, vil jeg hellere tale om "personalisering" i stedet for "tilpasning". Lad os se nærmere på, hvordan denne personalisering fungerer.
Når man bruger LLM'er, er der grundlæggende to metoder til at finjustere modellen, så den producerer bedre kvalitet på inferenstidspunktet, altså det tidspunkt hvor den giver sit svar.
Lad os først tage et kig på parameterjusteringen.
Det kan være en skræmmende opgave at opdatere parametrene for en LLM. Husk, at selv små LLM'er har milliarder af parametre. Det er en forholdsvis dyr opgave at opdatere dem, og ikke noget, der normalt ligger ingen for den typiske forbrugers rækkevidde, da omkostningerne og kompleksiteten ved at gøre det simpelthen er for høj.
Til maskinoversættelse vil vi normalt starte med en instruktionsjusteret LLM-model. Det er en model, der er blevet finjusteret til at være mere nyttig og til at følge instruktioner i stedet for blot at forudsige de næste ord. Efter finjusteringen klarer modellen sig bedre på en række områder, f.eks. opsummering, klassificering og maskinoversættelse. Du får flere oplysninger om, hvilken model du skal vælge i fremtidige blogindlæg i denne serie.
De instruktionsoptimerede LLM'er er et godt udgangspunkt for yderligere kundespecifikke optimeringer. Ved hjælp af metoden Parameter Efficient Fine-Tuning eller PEFT kan vi finjustere en instrueret model med kundedata på en kort og mere omkostningseffektiv måde.
Hos LanguageWire er vores foretrukne PEFT-metode LoRA (Low-Rank Adaption), som normalt indebærer opdatering af ca. 1,4-2,0 % af modelvægtene. Det betyder, at arbejdet med at tilpasse er rimeligt, men også overraskende effektivt. Som du kan se i tabellen nedenfor, konkluderer forfatterne af LoRA-artiklen, at LoRA kan vise sig at være endnu mere effektiv end en fuld finjustering af alle modelparametrene!
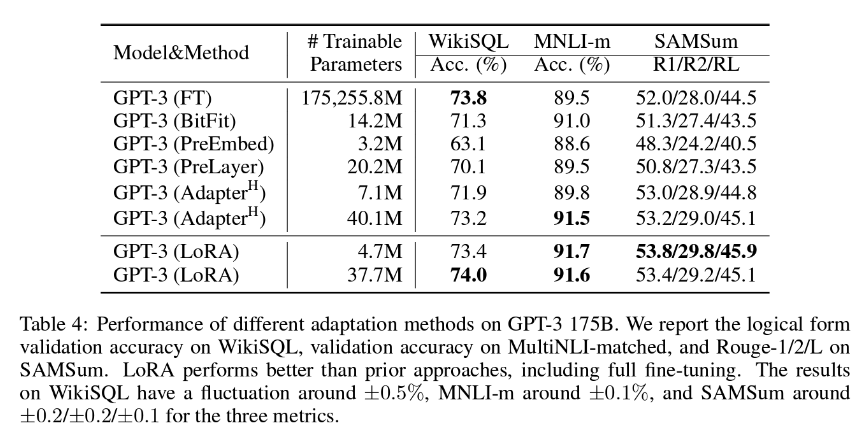
For at opnå de bedste resultater med denne metode er vi nødt til at have adgang til en stor mængde træningsdata af høj kvalitet med tilhørende kilde- og måltekster. Hvis du allerede har en betydelig oversættelseshukommelse, kan den sandsynligvis bruges til dette formål. LanguageWires AI-team arbejder konstant på at finde frem til den ideelle størrelse på oversættelseshukommelsen til finjustering med LoRA.
Lad os nu gå videre til den anden tilgang, kontekstbaseret læring eller Few-Shot Learning.
Kontekstbaseret læring er en metode, hvor modellen løbende lærer af et lille antal eksempler, der introduceres af en specialfremstillet prompt. Det er også kendt som "Few-Shot Learning".
I forbindelse med maskinoversættelse fungerer Few-Shot Learning som følger:
Few-Shot Learning til maskinoversættelse har en positiv indvirkning på, hvor flydende teksten bliver, tone of voice og brug af terminologi. Det kræver færre eksempler at arbejde med, maksimalt tre til fem. Faktisk bliver resultatet ikke bedre, hvis du vælger et større antal, så du får ikke gavn af at have hele din oversættelseshukommelse med i en enkelt prompt. Eksperimenter har vist, at LLM'er ikke håndterer store prompts så godt, og at kvaliteten af resultaterne endda kan blive dårligere!
Det er gennem en kombination af fordelene ved LoRA og Few-Shot Learning, at vi kan gennemføre effektive optimeringer i en Large Language Model, der i sidste ende fører til hyperpersonaliseret maskinoversættelse i topkvalitet.
Ingen af disse metoder ville fungere uden et stort sæt opdaterede tosprogede tekstkorpusser i høj kvalitet i forskellige sprogpar. Dine oversættelseshukommelser er den perfekte kilde til et sådant datasæt.
Men før de kan bruges, skal du overveje flere vigtige aspekter:
Hvis du bruger LanguageWires platform, sørger det automatiserede system til håndtering af oversættelseshukommelser at gøre det for dig, og du behøver ikke foretage dig noget manuelt.
Hvis du har en eksisterende ekstern oversættelseshukommelse, som du gerne vil bruge sammen med vores platform og maskinoversættelsesydelser, kan vores engineers gøre det muligt. LanguageWires engineers har udarbejdet import af API'er, oprydningsscripts og sprogkvalitetsvurderingsværktøjer, der hjælper dig med at få mest muligt ud af dit mest værdifulde sproglige værktøj.
Så hvordan samler vi alt dette til et typisk oversættelsesprojekt? Lad os se på et eksempel.
LanguageWire tilbyder en løsning, der er fuldt integreret i vores teknologiske økosystem. Det demonstreres i figur 1 nedenfor.
I dette eksempel har vi taget et simpelt workflow, hvor en kunde gerne vil oversætte PDF- eller Word-filer. Brugeren uploader ganske enkelt filerne via LanguageWires projektportal. Derfra orkestreres alt automatisk:
FIGUR 1: Et enkelt oversættelsesprojekt i den eksisterende LanguageWire Platform

I eksempel 2 fokuserer vi på trinnet før oversættelse ved hjælp af maskinoversættelse baseret på LLM-teknologi. Som det fremgår af figur 2 nedenfor, spiller kundens sproglige data en central rolle.
FIGUR 2: Et eksempel på oversættelse ved hjælp af en Large Language Model med en blanding af LoRA-tilpasninger og optimerede tekstbaserede læringsprompts.
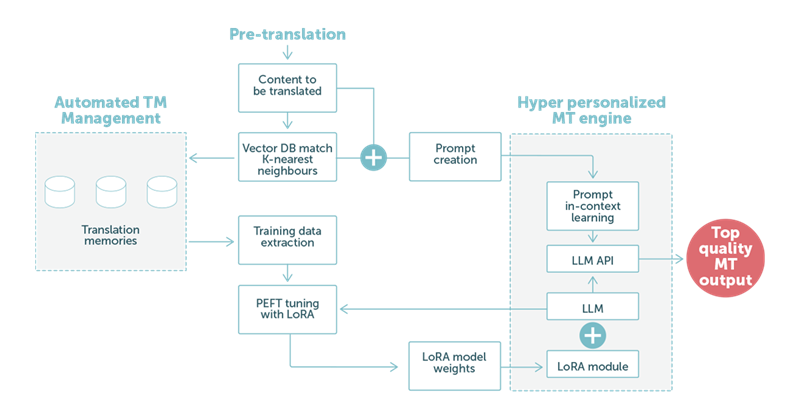
Når vores specialfremstillede prompt håndteres af LLM'en, vil de specialfremstillede vægte i LoRA-modulet være med til at sikre maskinoversættelse i topkvalitet. Når det er afsluttet, kører outputtet automatisk videre til næste trin i processen. Det vil typisk være en efterredigering med en menneskelig ekspert i kredsløbet for at opnå maksimal kvalitet.
Kort sagt: Vores kunder kan regne med endnu bedre maskinoversættelse. Maskinoversættelsen kan automatisk tilpasse sig forskellige kontekster, f.eks. forskellige virksomhedsvertikaler, og tilpasse sig den forventede tone of voice og valg af ord i den vertikal.
Det vil ikke kun reducere efterredigeringsudgifterne, men også gøre oversættelserne hurtigere at levere. Det vil også åbne op for et bredere anvendelsesområde for direkte brug af MT-outputtet uden menneskelige eksperter i loopet.
Som vi nævnte tidligere, er Large Language Models meget fleksible. LanguageWires AI-team undersøger mange andre områder, der kan have gavn af LLM-teknologi.
I øjeblikket kigger vi på:
Automatisk sprogkvalitetsevaluering. LLM'en kan kontrollere oversættelsen af en menneskelig ekspert eller maskinoversættelsesoutputtet af en anden model og byde ind med en kvalitetsscore. Det kan reducere udgifterne til korrekturlæsning betydeligt. Den bagvedliggende MTQE-teknologi (Machine Translation Quality Estimation) kan også anvendes i andre use cases.
Hjælp til forfatning af indhold. Ved hjælp af en kombination af PEFT med LoRA og Few-Shot Learning kan vi personalisere LLM-modellen, så den fokuserer på produktion af indhold. En kunde kan levere nøgleord og metadata, der gør det muligt for modellen at lave en tekst, der bruger en virksomhedstilpasset tone of voice og ordvalg.
LLM'en kan yderligere tilpasses med data fra termbaser.
Og der er meget mere på vej. Hold øje med flere blogindlæg i de kommende uger om AI og fremtiden for LLM'er hos LanguageWire.
Andre relevante artikler
Jeres rejse mod en effektiv og strømlinet håndtering af indhold på tværs af mange sprog starter her! Fortæl os om jeres behov, så skræddersyr vi den perfekte løsning til din virksomhed.


