
 Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Roeland Hofkens , Chief Product & Technology Officer, LanguageWire
Große Sprachmodelle (Large Language Models – LLMs) haben die Welt im Sturm erobert.
Einige dieser Modelle, darunter GPT-4 von OpenAI und PaLM2 von Google, sind mit einem mehrsprachigen Datensatz geschult worden und sollten – zumindest theoretisch – auch sehr gut in der Lage sein, maschinelle Übersetzungen durchzuführen.
Aber können sie das wirklich? Wie können wir die Möglichkeiten von großen Sprachmodellen für maschinelle Übersetzung voll ausschöpfen? In diesem technischen Artikel werden wir uns genauer ansehen, wie LLMs im Zusammenhang mit maschineller Übersetzung arbeiten und wie sie in ein Translation-Management-System (TMS) eingebunden werden könnten.
Die meisten gängigen maschinellen Übersetzungstools wie Google Translate basieren auf neuronalen Modellen mit Transformer-Architektur. Diese Modelle wurden speziell für eine Aufgabe entwickelt: maschinelle Übersetzung. Sie sind sofort einsatzbereit und erfüllen bereits sehr gut Aufgaben, die für die Übersetzung von allgemeinen Inhalten erforderlich sind. Bei komplexen und spezifischen Inhalten kann es jedoch vorkommen, dass die richtige Terminologie fehlt und der Stil unzureichend ist.
Daher ist es sinnvoll, diese Modelle mit zusätzlichen Unternehmensdaten zu optimieren, damit sie spezielle Begriffe und Formulierungen berücksichtigen. Mithilfe verschiedener Anpassungsmethoden lernt das Modell, den Ton und die Terminologie Ihres Unternehmens zu verwenden, was dann zu besseren Ergebnissen bei der maschinellen Übersetzung führt
Große Sprachmodelle basieren in der Regel ebenfalls auf Transformer-Architekturen. Im Vergleich zu den neuronalen maschinellen Übersetzungen (NMT), die im vorherigen Abschnitt beschrieben wurden, werden sie jedoch mit viel größeren Textmengen trainiert und enthalten mehr Modellparameter. LLMs enthalten Milliarden von Parametern, während es bei zweisprachigen NMT-Modellen mit einer einzigen Aufgabe nur einige hundert Millionen sind. Dadurch werden LLM-Varianten flexibler und „intelligenter“, wenn es um die Interpretation von Benutzeranweisungen oder Eingabeaufforderungen (Prompts) geht. Diese neue Technologie eröffnet viele neue Möglichkeiten bei der Anpassung der Modelle mit Unternehmensdaten. Da dieser Ansatz so leistungsfähig ist, spreche ich lieber von „Personalisierung“ anstatt von „Anpassung“. Schauen wir uns genauer an, wie diese Personalisierung funktioniert.
Bei der Verwendung von LLMs gibt es im Grunde zwei Ansätze zur Feinabstimmung des Modells, damit es zum Inferenzzeitpunkt eine bessere Qualität liefert – also zu dem Zeitpunkt, an dem es seine Antworten generiert.
Untersuchen wir zunächst die Parametereinstellung.
Die Aktualisierung der Parameter eines LLM kann eine abschreckende Aufgabe sein. Denken Sie daran, dass selbst kleine LLMs Milliarden von Parametern haben. Die Aktualisierung ist eine rechnerisch sehr aufwendige Aufgabe, die für einen typischen Nutzer in der Regel nicht machbar ist, da die Kosten und die Komplexität dafür einfach zu hoch sind.
Für die Zwecke der maschinellen Übersetzung beginnen wir in der Regel mit einem LLM-Modell, das auf Anweisungen abgestimmt ist („instruction-tuned“). Dies ist ein Modell, das so feinabgestimmt wurde, dass es nützlicher ist und Anweisungen befolgt, statt nur einfach die nächsten Wörter vorherzusagen. Nach der Feinabstimmung erbringt das Modell bei einer Vielzahl von Aufgaben wie Zusammenfassung, Klassifizierung und maschinelle Übersetzung eine bessere Leistung. Weitere Informationen darüber, welches Modell gewählt werden sollte, bringen wir in kommenden Blogbeiträgen aus dieser Reihe.
Die anweisungsorientierten LLMs sind ein guter Ausgangspunkt für weitere kundenspezifische Optimierungen. Mit einer Methode mit der Bezeichnung Parameter-effiziente Feinabstimmung (PEFT) können wir ein angewiesenes Modell mit Kundendaten in einer kurzen, kostengünstigeren Weise verfeinern.
Unsere bevorzugte PEFT-Methode bei LanguageWire ist LoRA (Low-Rank-Adaption), die in der Regel die Aktualisierung von etwa 1,4 bis 2,0 % der Modellgewichtung umfasst. Der Anpassungsaufwand ist angemessen, aber auch überraschend effektiv. Wie Sie der folgenden Tabelle entnehmen können, kommen die Autoren der LoRA-Studie zu dem Schluss, dass LoRA sich als noch effektiver erweisen kann als eine vollständige Feinabstimmung aller Modellparameter!
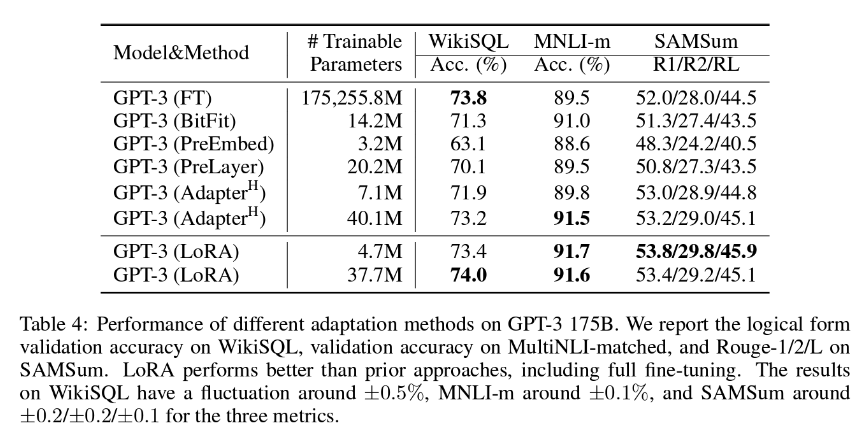
Um mit dieser Methode die besten Ergebnisse zu erzielen, benötigen wir Zugriff auf eine große Menge hochwertiger Trainingsdaten mit passenden Quell- und Zieltexten. Wenn Sie bereits ein großes Translation Memory aufgebaut haben, kann es wahrscheinlich für diesen Zweck verwendet werden. Das KI-Team von LanguageWire arbeitet kontinuierlich daran, die ideale Größe des Translation Memory für die LoRA-Abstimmung zu ermitteln.
Kommen wir nun zum zweiten Ansatz, dem kontextbezogenen Lernen oder Few-Shot-Lernen.
Kontextbezogenes Lernen ist eine Methode, bei der das Modell spontan aus einer kleinen Anzahl von Beispielen lernt, die durch eine speziell angefertigte Aufforderung eingeführt werden. Dies ist wird auch als Few-Shot-Lernen bezeichnet.
Im Zusammenhang mit maschineller Übersetzung funktioniert das Few-Shot-Lernen folgendermaßen:
Das Few-Shot-Lernen für MT wirkt sich positiv auf den Stil, den Ton und die Einhaltung der Terminologie aus. Dafür werden weniger Beispiele benötigt, maximal drei bis fünf. Durch mehr Inhalte verbessert sich die Effizienz nicht, so dass es nicht sinnvoll ist, Ihr gesamtes Translation Memory in einer einzigen Eingabeaufforderung zu integrieren. Versuche haben gezeigt, dass LLMs große Promptkontexte nicht so gut handhaben können und sich die Qualität der Ergebnisse sogar verschlechtern könnte!
Durch die Kombination der Vorteile von LoRA und Few-Shot-Lernen können wir im großen Sprachmodell wirkungsvolle Optimierungen umsetzen, die letztendlich zu hyperpersonalisierten, hochwertigen maschinellen Übersetzungen führen.
Keine dieser Methoden würde ohne einen großen Satz an hochwertigen, aktuellen zweisprachigen Textkorpora mit verschiedenen Sprachkombinationen funktionieren. Ihre Translation Memories sind eine ideale Quelle für diesen Datensatz.
Bevor sie aber verwendet werden können, müssen Sie einige wichtige Faktoren berücksichtigen:
Wenn Sie die LanguageWire-Plattform nutzen, übernimmt das automatische TM-Management diese Aufgaben für Sie und Sie brauchen nichts weiter zu unternehmen.
Falls Sie über ein externes Translation Memory verfügen, das Sie mit unserer Plattform und unseren maschinellen Übersetzungslösungen verwenden möchten, können unsere Experten dies ermöglichen. Unsere Teams bei LanguageWire haben APIs, Skripte zur Bereinigung von Translation Memories und Tools zur Überprüfung der Qualität der TMs entwickelt, damit Sie Ihre mehrsprachigen Daten optimal einsetzen können.
Wie bündeln wir alle diese Elemente bei einem typischen Übersetzungsprojekt? Sehen wir uns ein Beispiel an.
LanguageWire bietet eine Lösung an, die vollständig in unser Technologie-Ökosystem integriert ist. Dies wird in groben Zügen in Abb. 1 unten veranschaulicht.
Das Beispiel beschreibt einen einfachen Workflow, bei dem ein Kunde PDF- oder Office-Dateien übersetzen möchte. Der Nutzer lädt die Dateien für das Projekt auf die Plattform von LanguageWire hoch. Von nun an wird alles automatisch ausgeführt:
ABB. 1: Ein einfaches Übersetzungsprojekt auf der LanguageWire-Plattform

Im Beispiel 2 konzentrieren wir uns auf den Vorübersetzungsschritt mit maschineller Übersetzung auf Basis der LLM-Technologie. Wie in Abb. 2 unten dargestellt, kommt den Sprachdaten des Kunden eine zentrale Rolle zu.
ABB. 2: Ein Beispiel für eine Übersetzung, die ein großes Sprachmodell mit einer Kombination aus LoRA-Anpassungen und optimierten Eingabeaufforderungen für kontextbezogenes Lernen verwendet.
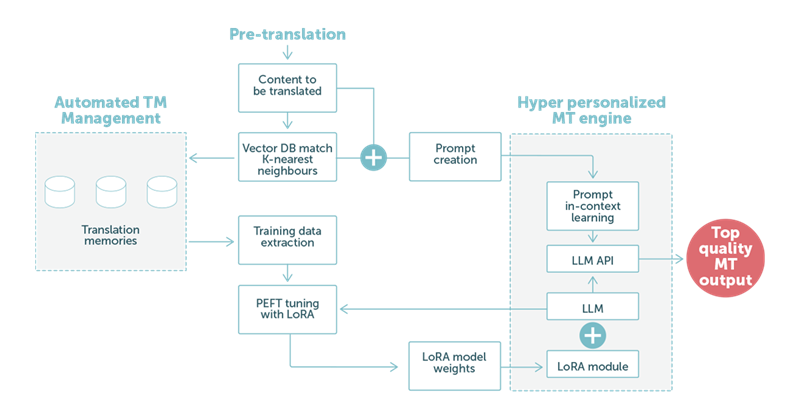
Wenn unsere speziell angefertigte Eingabeaufforderung vom LLM bearbeitet wird, tragen die angepassten Gewichtungen im LoRA-Modul zur Ausgabe einer hochwertigen maschinellen Übersetzung bei. Ist diese abgeschlossen, wird sie automatisch zum nächsten Schritt im Prozess weitergeleitet. Dabei handelt es sich in der Regel um eine Nachbearbeitung durch einen Sprachexperten, um eine optimale Qualität zu gewährleisten.
Kurz gesagt: Unsere Kunden können eine noch bessere maschinelle Übersetzung erwarten. Die maschinelle Übersetzung kann sich automatisch an unterschiedliche Kontexte anpassen, z. B. an verschiedene Geschäftsbereiche, und sich an die gewünschte Tonalität und Wortwahl dieses Bereichs anpassen.
Dies reduziert nicht nur die Kosten für die Nachbearbeitung, sondern beschleunigt auch die Lieferung von Übersetzungen. Darüber hinaus wird der Anwendungsbereich für die direkte Nutzung der maschinellen Übersetzung erweitert, ohne dass Sprachexperten beteiligt sind.
Wie bereits erwähnt, sind große Sprachmodelle sehr flexibel. Das KI-Team von LanguageWire untersucht derzeit zahlreiche weitere Bereiche, die von der LLM-Technologie profitieren könnten.
Wir beschäftigen uns derzeit unter anderem mit folgenden Themen:
Automatisierte Überprüfung der Sprachqualität. Das LLM könnte die Übersetzung eines Sprachexperten oder die maschinelle Übersetzung eines anderen Modells prüfen und eine Qualitätsbewertung abgeben. Dies könnte die Kosten für das Korrekturlesen beträchtlich senken. Die zugrunde liegende MTQE-Technologie (Qualitätsbewertung durch maschinelle Übersetzung) kann auch auf andere Einsatzbereiche angewendet werden.
Unterstützung bei der Content-Erstellung. Durch die Kombination von PEFT mit LoRA und Few-Shot-Lernen können wir das LLM-Modell so personalisieren, dass wir uns auf die Content-Erstellung konzentrieren können. Ein Kunde könnte Keywords und Metadaten zur Verfügung stellen, mit deren Hilfe das Modell einen Text erstellen kann, der die angepasste Tonalität und die Terminologie des Unternehmens verwendet.
Weitere Anpassung des LLM mithilfe von Daten aus Termbase-Datenbanken.
Und das ist noch längst nicht das Ende. Bleiben Sie auf dem Laufenden und lesen Sie in den kommenden Wochen weitere Blogbeiträge über KI und die Zukunft von LLMs bei LanguageWire.
Andere Artikel, die Sie interessieren könnten
Ihr Weg zu einem leistungsstarken, integrierten Sprachmanagement beginnt hier! Nennen Sie uns Ihre Anforderungen und wir finden die optimale Lösung für Ihr Unternehmen.


