
 Roeland Hofkens, Chief Product & Technology Officer, LanguageWire
Roeland Hofkens, Chief Product & Technology Officer, LanguageWire
Les grands modèles de langage (LLM) ont pris le monde d’assaut.
Certains de ces modèles, tels que le GPT-4 d’OpenAI et le PaLM2 de Google, ont été formés sur un ensemble de données multilingues et devraient, du moins en théorie, être très performants pour les tâches de traduction automatique.
Mais est-ce vraiment le cas ? Comment exploiter tout le potentiel des grands modèles de langage pour la traduction automatique ? Dans cette présentation technique approfondie, nous examinerons comment les LLM travaillent dans le cadre de la traduction automatique et comment ils peuvent être intégrés dans un système de gestion des traductions (TMS).
La plupart des outils de traduction automatique commerciaux actuels, tels que Google Traduction, sont basés sur des modèles neuronaux dotés d’une architecture de transformateur. Ces modèles sont spécialement conçus pour une seule tâche : la traduction automatique. Prêts à l’emploi, ils sont déjà très performants dans les tâches nécessaires à la traduction de contenu générique. Cependant, dans des contextes professionnels spécialisés, ils peuvent passer à côté du vocabulaire adéquat ou ne pas utiliser un style optimal.
Il est donc utile de personnaliser ces modèles avec des données d’entreprise supplémentaires en les formant à reconnaître vos termes et expressions personnalisés. Grâce à diverses méthodes de personnalisation, le modèle « apprend » à utiliser le ton et la terminologie de votre entreprise, ce qui permet d’obtenir de meilleurs résultats de traduction automatique.
Les grands modèles de langage sont généralement basés sur des architectures de transformateur. Cependant, par rapport aux modèles de traduction automatique neuronale (NMT) présentés dans la section précédente, ils sont formés sur des corpus de texte beaucoup plus importants et contiennent plus de paramètres de modèle. Les LLM contiennent des milliards de paramètres contre quelques centaines de millions pour les modèles NMT bilingues à tâche unique. Cela rend les modèles LLM plus flexibles et « plus intelligents » lorsqu’il s’agit d’interpréter les instructions de l’utilisateur ou les « invites ». Cette nouvelle technologie ouvre de nombreuses nouvelles possibilités en termes de personnalisation des modèles avec des données d’entreprise. En raison de la puissance de cette approche, je préfère parler en termes de « personnalisation » plutôt que de « customisation ». Découvrons comment fonctionne cette personnalisation.
Lors de l’utilisation des LLM, il existe essentiellement deux approches pour affiner le modèle, afin qu’il produise une meilleure qualité au moment de l’inférence, c’est-à-dire au moment où il génère sa réponse.
Examinons tout d’abord le réglage des paramètres.
La mise à jour des paramètres d’un LLM peut être une tâche difficile. N’oubliez pas que même les petits LLM ont des milliards de paramètres. Leur mise à jour est une tâche très coûteuse sur le plan informatique, qui est généralement hors de portée pour un consommateur moyen, car le coût et la complexité de cette opération sont tout simplement trop élevés.
En ce qui concerne la traduction automatique, nous commencerons généralement par un modèle LLM adapté aux instructions. Il s’agit d’un modèle qui a été affiné pour être plus utile et pour suivre les instructions, plutôt que de simplement prédire les mots suivants. Après réglage, le modèle sera plus performant pour une variété de tâches telles que la synthèse, la classification et la traduction automatique. Nous vous fournirons plus d’informations sur le modèle à choisir dans les prochains articles de cette série.
Les LLM adaptés aux instructions constituent un bon point de départ pour d’autres optimisations spécifiques au client. À l’aide d’une approche appelée Parameter Efficient Fine-Tuning (PEFT), nous pouvons affiner un modèle formé avec les données des clients plus rapidement et de manière plus rentable.
Chez LanguageWire, notre méthode PEFT préférée est LoRA ( Low-Rank Adaption), ce qui implique généralement une mise à jour d’environ 1,4 à 2,0 % des poids du modèle. Cela signifie que l’effort de personnalisation est raisonnable, mais aussi étonnamment efficace. Comme vous pouvez le voir dans le tableau ci-dessous, les auteurs de l’article sur LoRA concluent que LoRA peut s’avérer encore plus efficace que le réglage complet de tous les paramètres du modèle !
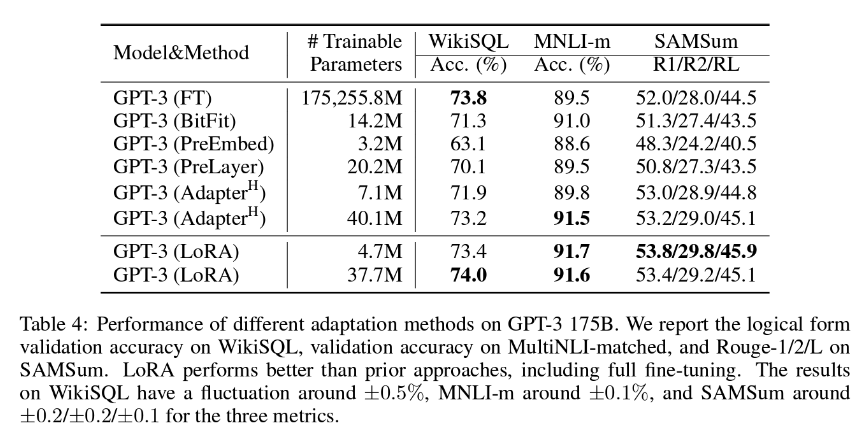
Pour obtenir les meilleurs résultats avec cette méthode, nous devons avoir accès à une grande quantité de données de formation de haute qualité avec des textes sources et cibles correspondants. Si vous avez déjà constitué une importante mémoire de traduction, vous pouvez probablement l’utiliser à cette fin. L’équipe d’IA de LanguageWire travaille en permanence à l’identification de la taille idéale de la mémoire de traduction pour le réglage LoRA.
Passons maintenant à la deuxième approche, l’apprentissage contextuel ou « few-shot learning ».
L’apprentissage contextuel est une méthode où le modèle apprend en direct à partir d’un petit nombre d’exemples présentés par une invite spécialement conçue. C’est ce que l’on appelle également « few-shot learning ».
Dans le cadre de la traduction automatique, le few-shot learning fonctionne de la manière suivante :
Le few-shot learning pour TA a un impact positif sur la fluidité, le ton et le respect de la terminologie. Elle nécessite moins d’exemples, trois à cinq au maximum. En effet, l’efficacité ne s’améliore pas avec des échantillons de plus grande taille et il n’est donc pas avantageux d’inclure l’ensemble de votre mémoire de traduction en une seule invite. Des expériences ont montré que les LLM ne gèrent pas très bien les contextes d’invite de grande taille et que la qualité des résultats peut même se détériorer !
C’est en combinant les avantages de LoRA et du few-shot learning que nous pouvons mettre en œuvre des optimisations performantes dans les grands modèles de langage, ce qui permet d’obtenir une traduction automatique hyper-personnalisée et de qualité supérieure.
Aucune de ces méthodes ne fonctionnerait sans un large ensemble de corpus de textes bilingues de haute qualité et à jour dans différentes combinaisons de langues. Vos mémoires de traduction constituent une source idéale pour cet ensemble de données.
Cependant, avant de pouvoir l’utiliser, vous devez tenir compte de plusieurs aspects importants :
Si vous utilisez la plateforme LanguageWire, le module automatisé de gestion des mémoires de traduction s’occupe de ces aspects pour vous et aucune action manuelle n’est nécessaire.
Si vous disposez d’une mémoire de traduction externe que vous souhaitez utiliser avec notre plateforme et nos services de traduction automatique, nos ingénieurs peuvent vous aider. Les ingénieurs de LanguageWire ont créé des API d’importation, des scripts de nettoyage et des outils d’évaluation de la qualité linguistique pour vous aider à tirer le meilleur parti de votre atout linguistique le plus précieux.
Comment réunir tous ces éléments pour un projet de traduction classique ? Prenons un exemple.
LanguageWire propose une solution entièrement intégrée à notre écosystème technologique. La figure 1 ci-dessous illustre les principales étapes du processus.
Dans cet exemple, nous avons pris un flux de travail simple dans lequel un client souhaite traduire des fichiers PDF ou Office. L’utilisateur télécharge simplement les fichiers de contenu à l’aide du portail de projets de LanguageWire. À partir de là, tout est orchestré automatiquement :
FIGURE 1 : Résultat d’un projet de traduction simple sur la plateforme LanguageWire existante

Dans l’exemple 2, nous nous concentrons sur l’étape de pré-traduction utilisant la traduction automatique basée sur la technologie LLM. Comme nous pouvons le voir dans la figure 2 ci-dessous, les données linguistiques du client jouent un rôle central.
FIGURE 2 : Exemple de traduction utilisant un grand modèle de langage avec une combinaison de personnalisations LoRA et d’invites d’apprentissage contextuelles optimisées.
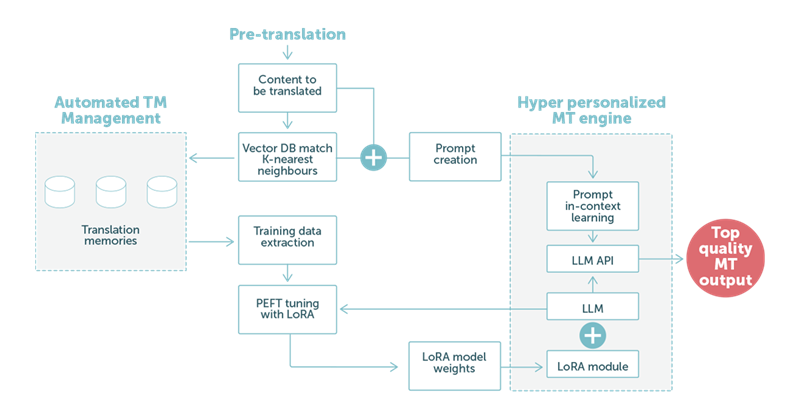
Lorsque notre invite spécialement conçue est traitée par le LLM, les poids personnalisés du module LoRA contribuent à un résultat de traduction automatique de qualité supérieure. Une fois cette étape terminée, le résultat passe automatiquement à l’étape suivante du processus. En général, il s’agit d’une tâche de post-édition avec un expert humain pour une qualité finale maximale.
En résumé : nos clients peuvent s’attendre à une traduction automatique encore plus performante. La TA peut s’adapter automatiquement à différents contextes, par exemple à différents secteurs d’activité, et s’aligner sur le ton attendu et le vocabulaire propre à ce secteur.
Non seulement cela réduira les coûts de post-édition, mais cela augmentera également la vitesse de livraison des traductions. Cela ouvrira également un champ d’application plus large pour utiliser directement les résultats de la TA, sans que des experts humains n’interviennent dans le processus.
Comme nous l’avons déjà dit, les grands modèles de langage sont très flexibles. L’équipe d’IA de LanguageWire étudie de nombreux autres domaines qui pourraient bénéficier de la technologie des LLM.
Nous menons actuellement des recherches sur les sujets suivants :
L’évaluation automatisée de la qualité linguistique. Le LLM pourrait vérifier la traduction d’un expert humain ou le résultat de la traduction automatique d’un autre modèle et donner une note de qualité. Cela pourrait réduire considérablement les coûts de révision. La technologie sous-jacente d’estimation de la qualité de la traduction automatique (MTQE) peut également être appliquée à d’autres cas d’utilisation.
Les assistants de création de contenu. À l’aide d’une combinaison de PEFT avec LoRA et de few-shot learning, nous pouvons personnaliser le modèle LLM pour qu’il se consacre aux tâches de création de contenu. Un client pourrait fournir des mots-clés et des métadonnées permettant au modèle de générer un texte qui utilise un ton et un vocabulaire personnalisés pour l’entreprise.
L’application d’une personnalisation supplémentaire du LLM avec des données provenant de bases terminologiques.
Et bien d’autres choses encore. Dans les semaines à venir, ne manquez pas les prochains articles sur l’IA et l’avenir des LLM chez LanguageWire.
Autres articles susceptibles de vous intéresser
Ouvrez-vous la voie vers une gestion efficace et harmonieuse de vos contenus en différentes langues ! Faites-nous part de vos besoins et nous créerons la solution sur mesure idéale pour votre entreprise.


